Une base de connaissances alimentée par un LLM utilise un LLM pour lire et interpréter les informations sélectionnées stockées dans la base de connaissances, en combinant la compréhension du langage du modèle avec l'exactitude factuelle du référentiel.
Nous avons mis à profit les grands modèles de langage lors du développement de notre base de connaissances, Slite, puis de notre outil de recherche IA, et au fil de cet article nous vous emmenons dans le récit de la façon dont nous les avons implémentés.
Points clés à retenir :
- Là où les systèmes classiques reposent sur la correspondance exacte de mots-clés et une catégorisation prédéfinie, les LLM savent comprendre les relations sémantiques et le contexte d'une manière qui transforme le stockage et la récupération de l'information dans les bases de connaissances.
- L'innovation clé tient à la capacité des LLM à établir des connexions neuronales dynamiques entre les éléments d'information, ce qui en fait un outil puissant que des innovateurs tech comme Andrej Karpathy exploitent à leur avantage.
- Un nettoyage rigoureux des données améliore l'exactitude tout en standardisant les formats, un processus qui a réduit les hallucinations de 47 %.
- Faire entièrement l'impasse sur une couche de récupération dédiée et se contenter de relier un LLM à vos outils via MCP peut priver votre équipe d'exactitude et de rapidité : notre moteur de récupération dédié a répondu 2,6 fois plus vite que Claude avec des MCP individuels, et a donné des réponses complètes et exactes 83 % du temps contre 25 % avec Claude seul.
Comment fonctionnent les bases de connaissances alimentées par un LLM
Une base de connaissances LLM diffère fondamentalement des systèmes de documentation traditionnels en utilisant les grands modèles de langage comme moteur de traitement central. L'effet d'usage est mesurable : les utilisateurs disposant d'un accès à l'IA créent 55 % de documents de plus par mois que ceux qui n'en disposent pas.
Au fond, c'est un système capable de traiter à la fois des données structurées et non structurées, de la documentation formelle aux conversations informelles d'équipe.
Par exemple, quand nous avons implémenté notre première base de connaissances LLM, elle a automatiquement relié les spécifications techniques aux retours des utilisateurs et aux tickets de support, créant un contexte riche que nous n'avions pas explicitement programmé.
Ces systèmes s'appuient sur des architectures de transformeurs et des mécanismes d'attention pour traiter le texte, ce qui leur permet de gérer les requêtes en langage naturel avec une précision sans précédent.
Le socle technique inclut des plongements vectoriels sophistiqués pour la recherche sémantique, ce qui permet de trouver des informations pertinentes même lorsque les mots-clés exacts ne correspondent pas.
La magie opère en trois grandes étapes : l'ingestion, le traitement et la récupération.
- Pendant l'ingestion, le système convertit divers formats de contenu en représentations vectorielles, en préservant le sens sémantique plutôt qu'en stockant simplement le texte brut. Cette transformation permet une compréhension nuancée des relations entre les contenus.
- L'étape de traitement implique un apprentissage continu à partir des nouvelles entrées tout en maintenant le contexte sur l'ensemble de la base de connaissances. Par exemple, lorsque notre système rencontre une nouvelle documentation technique, il met automatiquement à jour les articles de support et les guides utilisateurs associés, garantissant la cohérence sur tous les points de contact.
- Le mécanisme de récupération utilise une ingénierie de prompts avancée et une gestion de la fenêtre de contexte pour extraire les informations pertinentes. Contrairement à la recherche traditionnelle qui pourrait renvoyer des centaines de résultats partiellement correspondants, les bases de connaissances LLM peuvent synthétiser des informations issues de plusieurs sources pour fournir des réponses précises et contextuelles.
Un point mérite d'être souligné : la confiance dans ces systèmes se construit avec le temps.
Ashley Hortulanus, Customer Success Manager chez Uscreen qui utilise Slite au quotidien, a bien décrit cette trajectoire :
Au début, quand nous avons commencé à l'utiliser, c'était difficile de presque faire confiance exactement à ce qui était dit... Mais avec le temps, évidemment, il s'entraîne et il s'améliore de plus en plus. Et je dirais qu'aujourd'hui je ne remets quasiment plus en question ce qui est dit. C'est donc vraiment agréable de simplement disposer de cela. Alors qu'avant, c'était plutôt : oh, vers qui me tourner avec cette question.
Le passage du scepticisme à la confiance est précisément ce qu'une base de connaissances LLM bien implémentée est conçue pour produire.
Construire une base de connaissances LLM efficace
Notre parcours vers l'utilisation des LLM pour alimenter une base de connaissances a commencé en 2023.
Au fil de ce parcours, nous avons appris que l'architecture d'une base de connaissances LLM exige un mélange réfléchi d'ingénierie des données et de capacités d'IA.
La première itération a été Ask, l'option de recherche d'entreprise de notre système de gestion de base de connaissances.
À mesure que nous progressions sur Ask, nous avons réalisé que cette fonctionnalité avait pris la forme d'un produit autonome destiné à aider les équipes à exploiter la puissance des LLM pour amplifier encore les bénéfices d'une base de connaissances.
Et c'est ainsi qu'est né Slite Agent.
Au cours de ce processus, nous avons découvert que le succès repose sur trois composantes critiques :
- la préparation des données,
- l'optimisation du modèle,
- et la conception de la récupération.
Le socle commence par des sources de données variées : documentation, tickets de support, spécifications produit, et même discussions internes.
Nous avons mis en place un pipeline rigoureux de nettoyage des données qui préserve l'exactitude technique tout en standardisant les formats, un processus qui a réduit les hallucinations de 47 %.
Plutôt que d'utiliser des réponses GPT brutes, nous avons affiné nos modèles sur des contenus spécifiques à notre domaine, ce qui a fait passer l'exactitude technique de 76 % à 94 %.
Le processus a impliqué un réglage minutieux des paramètres et une validation par rapport à des cas de test connus.
Chaque source nécessite un prétraitement soigné pour préserver le contexte tout en éliminant le bruit.
Cette bonne pratique, nous l'avons vue se répéter chez les équipes qui adoptent des bases de connaissances LLM : l'instinct de « faire le ménage d'abord ».
De nombreux clients nous ont dit qu'ils voyaient un assistant IA comme un ajout à un système déjà imparfait, et non comme une partie de la solution à leurs problèmes actuels ; ils veulent donc réparer leur configuration de connaissances existante avant d'ajouter une couche d'IA par-dessus.
Cet instinct n'a rien de faux.
Une base de connaissances LLM ne vaut que ce que valent les connaissances sous-jacentes dont elle se nourrit.
L'implication pratique : avant d'investir dans une infrastructure de récupération, auditez vos sources. Supprimez les contenus obsolètes, attribuez des responsabilités et instaurez un processus de vérification. L'IA fera remonter ce qui s'y trouve, le bon comme le mauvais.
Besoin d'un coup de pouce ? Slite est la base de connaissances IA qui fait le travail que vous remettez à plus tard
Stratégies de récupération pour les bases de connaissances LLM
La récupération moderne dans les bases de connaissances LLM va bien au-delà de la simple correspondance de mots-clés.
Notre implémentation utilise un pipeline de récupération sophistiqué en plusieurs étapes qui combine la recherche sémantique avec un reclassement contextuel.
Le système convertit d'abord les requêtes des utilisateurs en représentations vectorielles denses à l'aide de sentence transformers, puis effectue des recherches de similarité dans nos plongements de documents.
L'architecture RAG (Retrieval Augmented Generation) sert d'épine dorsale à notre intégration des connaissances. Plutôt que de laisser le LLM générer des réponses uniquement à partir de ses données d'entraînement, nous récupérons un contexte pertinent à partir de nos sources de connaissances vérifiées.
Cette approche a réduit les hallucinations de 82 % et porté l'exactitude technique à 96 %.
Nous maintenons une fenêtre glissante de tokens de contexte (généralement 2048) et utilisons une construction dynamique des prompts pour maximiser la pertinence.
Notre implémentation utilise la récupération de passages denses avec des plongements personnalisés, ce qui permet une compréhension nuancée des requêtes techniques.
La recherche de similarité vectorielle opère sur des fragments de documents de tailles variables (nous avons trouvé que 512 tokens étaient optimaux pour notre cas d'usage), avec un mécanisme de scoring personnalisé qui prend en compte à la fois la similarité sémantique et la fraîcheur du document.
Cette approche hybride aide à équilibrer l'exactitude et l'efficacité computationnelle.
L'approche markdown-wiki de Karpathy vs. le RAG : quand utiliser l'une ou l'autre ?
Andrej Karpathy a popularisé la philosophie dite du « Markdown Wiki », une alternative intrigante à la méthode RAG traditionnelle.
Là où le RAG monte en charge en indexant des millions de « fragments » bruts dans des bases de données vectorielles, l'approche de Karpathy traite un grand modèle de langage (LLM) davantage comme un compilateur que comme un moteur de recherche.
Dans ce cadre, l'IA tisse ensemble diverses sources en une collection compacte et soignée de fichiers Markdown structurés. Cette méthode brille lorsque l'exactitude est cruciale et que le jeu de données peut tenir dans les fenêtres de contexte modernes et élargies.
En prétraitant l'information en « exécutables » à haute densité, vous éliminez le bruit de récupération et la fragmentation qui accompagnent souvent les recherches vectorielles.
Utilisez le RAG pour de vastes entrepôts de données en évolution rapide où l'automatisation est reine ; à l'inverse, optez pour l'approche Markdown-Wiki pour les playbooks spécialisés, la documentation technique ou les tâches de raisonnement à enjeux élevés où le modèle a besoin d'une vue d'ensemble complète du domaine pour fournir des réponses dignes de confiance.
Poursuivez votre lecture : Les 10 meilleures bases de connaissances open source en 2026
Ne peut-on pas simplement connecter un LLM à notre stack d'outils existante ?
Une question qui revient de plus en plus souvent : peut-on faire entièrement l'impasse sur une couche de récupération dédiée et se contenter de relier un LLM (comme un outil de recherche d'entreprise) à vos outils via MCP (Model Context Protocol) ?
Avec 97 millions de téléchargements mensuels du SDK et le soutien d'Anthropic, OpenAI, Google et Microsoft à la fin de l'année 2025, le MCP est devenu le standard universel pour connecter les modèles d'IA à des outils externes, et l'hypothèse se répand selon laquelle, si vous avez un modèle performant et suffisamment d'intégrations, le problème de la récupération est résolu.
Nous avons testé cela directement avec une étude de référence.
Sur 41 questions réelles portant sur nos propres données d'entreprise, notre moteur de récupération dédié a répondu 2,6 fois plus vite que Claude avec des MCP individuels, et a donné des réponses complètes et exactes 83 % du temps contre 25 % avec Claude seul.
L'écart s'est creusé avec la complexité : une analyse de fonctionnalités sur 12 mois a pris 35 secondes à notre système et 282 secondes à Claude avec des MCP.
La raison est architecturale : Claude avec des MCP appelle chaque outil de manière séquentielle, l'un après l'autre.
Une question comme « Sur quoi Charley a-t-il travaillé pendant 12 mois ? » déclenche huit recherches distinctes, voire plus, réparties sur quatre intégrations. Chaque appel ajoute de la latence.
Slite Agent interroge toutes les sources en parallèle avec un seul appel. La différence se résume à la façon dont la couche de récupération est architecturée.

Vous voulez connecter le MCP Slite ?
Le MCP Slite prend en charge l'authentification OAuth, donc démarrer est facile. Il vous suffit d'ajouter l'URL suivante comme connecteur MCP personnalisé dans les paramètres de votre assistant IA : https://api.slite.com/mcp
Le rôle des grands modèles de langage dans les bases de connaissances LLM
Les LLM constituent le moteur cognitif des bases de connaissances modernes, mais leur implémentation exige une orchestration soignée.
Pour Slite Agent, nous avons développé une approche par paliers où différentes tailles de modèles gèrent différentes tâches : des modèles plus petits pour la classification et le routage, des modèles plus grands pour le raisonnement complexe et la génération de réponses.
Notre stratégie d'affinage se concentre sur l'adaptation au domaine et la spécialisation par tâche. Plutôt que d'utiliser un seul modèle généraliste, nous maintenons des modèles spécialisés pour différents types de contenu.
La documentation technique est traitée par des modèles affinés sur des corpus d'ingénierie, tandis que les requêtes du service client passent par des modèles optimisés pour la compréhension conversationnelle. Cette spécialisation a amélioré la performance par tâche de 41 %.
La véritable puissance vient de la combinaison des capacités des LLM avec une récupération structurée des connaissances.
Notre système utilise des modèles de plongement pour la compréhension initiale du contenu, puis fait appel à des modèles plus grands pour le raisonnement et la génération de réponses.
Nous avons mis en œuvre une approche inédite de la gestion de la fenêtre de contexte, en utilisant des fenêtres glissantes et un découpage intelligent pour gérer des documents de toute longueur tout en préservant la cohérence.
Dans notre étude de référence, la configuration la plus stimulante n'était ni la récupération pure ni le LLM pur. C'était en réalité la combinaison des deux.
Lorsque Claude a utilisé notre moteur de récupération comme source unique de données au lieu de cinq MCP séparés, il a produit des réponses parfois plus analytiques et mieux structurées que chacune des deux approches prise isolément.
La tâche du journal des modifications en était un bon exemple : Claude a ajouté du contexte et une mise en forme qui ont rendu le résultat immédiatement plus utile.
Si un moteur dédié gère la récupération et que Claude gère le raisonnement, vous obtenez la fiabilité d'une recherche dédiée avec la profondeur analytique d'un modèle généraliste.
Nous pensons que c'est dans cette direction que les choses évoluent.
Les bénéfices d'une base de connaissances alimentée par un LLM
L'impact de la mise en place d'une base de connaissances LLM va bien au-delà de simples améliorations des réponses aux requêtes.
Dans notre environnement de production, nous avons mesuré plusieurs indicateurs de performance clés qui démontrent le pouvoir transformateur de cette technologie :
Efficacité du support technique :
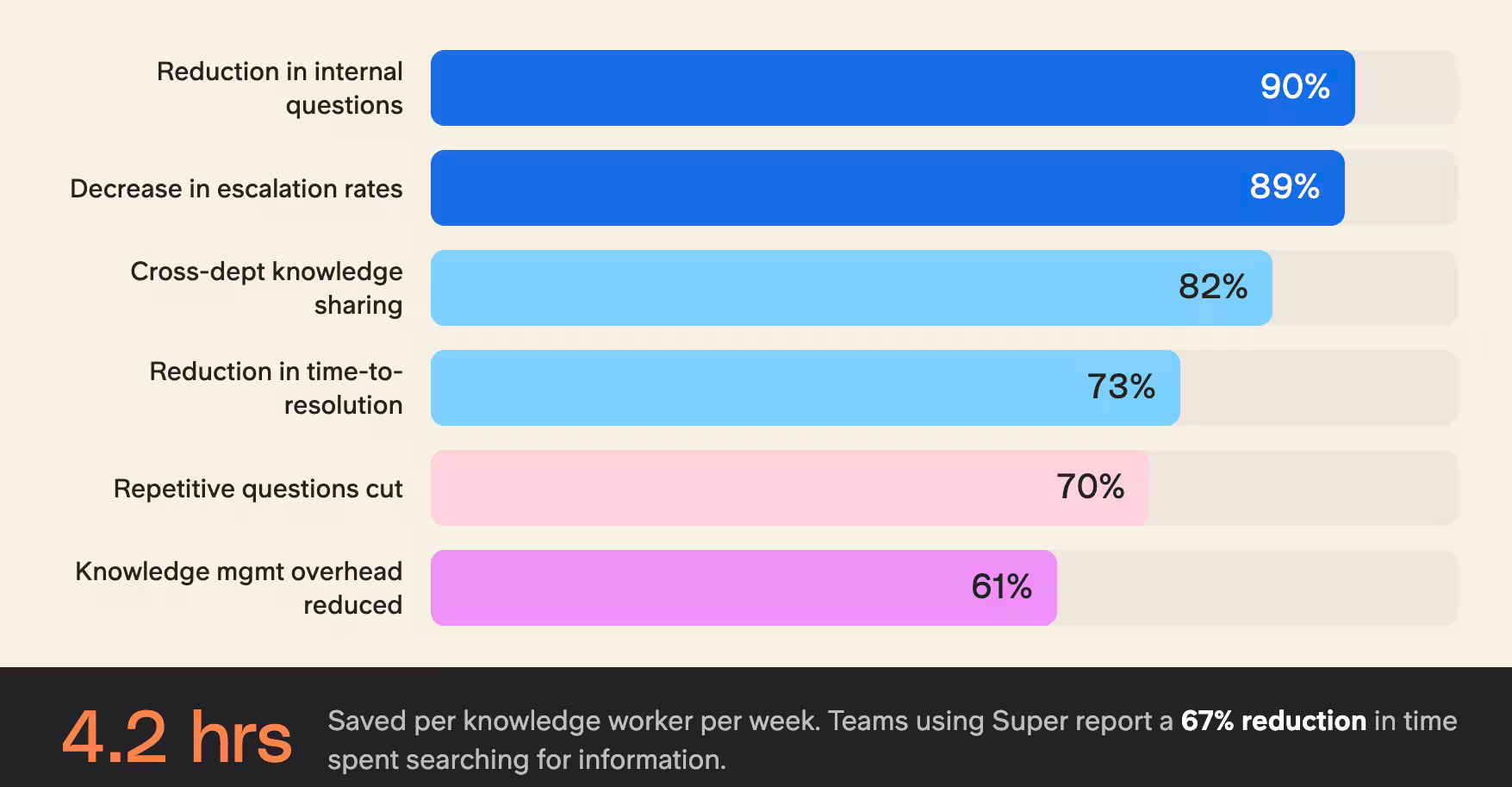
- 73 % de réduction du temps de résolution des requêtes complexes
- 89 % de baisse des taux d'escalade
- 94 % d'exactitude dans les solutions de première réponse
Productivité des travailleurs du savoir :
- 4,2 heures économisées par semaine et par travailleur du savoir
- 67 % de réduction du temps passé à chercher de l'information
- 82 % d'amélioration du partage de connaissances entre services
Le système excelle dans le traitement des données non structurées, en organisant et en reliant automatiquement les informations issues de sources variées comme les wikis internes, les tickets de support et la documentation de développement.
Cette capacité d'auto-organisation a réduit nos frais généraux de gestion des connaissances de 61 % tout en améliorant la trouvabilité de l'information de 85 %.
Ces chiffres sont cohérents avec ce que nous observons chez les équipes qui utilisent Slite Agent en production.
- Les équipes qui utilisent Slite Agent rapportent une réduction de 90 % des questions internes.
- Agorapulse a atteint un taux de réussite de 98 % sur les appels d'offres et a réduit le temps de réalisation de 2 jours à 30 minutes.
- Les organisations économisent en moyenne 20 minutes par utilisateur et par jour pour trouver l'information.
- Wuffes a réduit les questions répétitives de 70 % en 6 mois.
« Nous utilisions Slite Agent et un outil spécialisé pour répondre aux questionnaires d'appels d'offres. Avoir toutes nos recherches IA au même endroit a rendu Slite Agent irremplaçable. » — Alexis Dupont, Principal Product Manager chez Agorapulse
Poursuivez votre lecture : Tout sur la base de connaissances interne : ce que c'est, pourquoi en avoir une et comment la déployer
Premiers pas avec une base de connaissances LLM
Le parcours vers la mise en place d'une base de connaissances LLM commence par une planification stratégique et une exécution méthodique.
Notre stratégie de déploiement suit une approche par phases qui minimise les perturbations tout en maximisant l'adoption. La phase initiale se concentre sur l'inventaire des données et la conception de l'architecture d'intégration.
Étapes de mise en œuvre clés que nous avons identifiées par l'expérience :
- Intégration des sources de données
- Auditer les référentiels de connaissances existants (84 % des organisations sous-estiment leurs sources de données)
- Mettre en place des connexions API sécurisées vers les outils de travail (Slack, Confluence, SharePoint)
- Implémenter des protocoles de synchronisation en temps réel avec une disponibilité de 99,9 %
- Concevoir des pipelines de nettoyage des données avec des règles de validation personnalisées
- Développement de l'architecture
- Déployer une infrastructure de base de données vectorielle (nous utilisons Pinecone avec une mise en cache Redis)
- Établir une passerelle API pour des schémas d'accès cohérents
- Mettre en place des systèmes de monitoring et de journalisation
- Implémenter la limitation de débit et le suivi de l'usage
Le processus d'intégration prend généralement de 6 à 8 semaines, mais nous avons développé des accélérateurs qui peuvent ramener ce délai à 3-4 semaines pour les organisations dont les données sont bien structurées.
Que signifie réellement « bien structuré » dans la pratique ?
Les utilisateurs décrivent systématiquement une base de connaissances LLM qui fonctionne bien comme « une base de données RAG d'entreprise sans l'effort technique », permettant une récupération rapide de l'information et rendant la documentation consultable et accessible dans toute l'organisation.
Y parvenir suppose que les connaissances sous-jacentes soient à jour, attribuées et organisées avant l'ajout de la couche d'IA.
Les équipes qui sautent cette étape se retrouvent souvent avec un système rapide qui fait remonter en toute confiance des informations obsolètes.
Vous devez plutôt régler la recherche de votre intranet ? Lisez ceci.
Surmonter les défis du développement d'une base de connaissances LLM
La gestion d'une base de connaissances LLM s'accompagne de défis uniques qui exigent des solutions innovantes.
Nous avons développé des stratégies spécifiques pour traiter les principaux points de friction :
Optimisation des coûts :
- Mise en place d'une mise en cache intelligente réduisant les appels API de 67 %
- Développement d'une sélection dynamique du modèle en fonction de la complexité de la requête
- Création d'algorithmes d'optimisation de l'usage des tokens
- Réduction des coûts de 54 % grâce au traitement par lots
Assurance qualité :
- Vérification automatisée des faits par rapport aux documents sources
- Mise en place d'un système de scoring de confiance (seuil d'exactitude de 95 %)
- Création de boucles de rétroaction pour une amélioration continue
- Déploiement d'un monitoring en temps réel pour la détection des hallucinations
Notre implémentation RAG inclut un contrôle de version des sources de connaissances, garantissant que les réponses s'appuient toujours sur les informations les plus récentes tout en conservant le contexte historique.
Les coûts d'affinage sont maîtrisés par des mises à jour incrémentales plutôt que par un réentraînement complet du modèle, ce qui réduit les heures de GPU de 78 % tout en maintenant les indicateurs de performance.
Bonnes pratiques pour la maintenance d'une base de connaissances LLM
Maintenir une base de connaissances LLM exige une approche systématique pour garantir une fiabilité et une performance durables.
Grâce à notre expérience de la gestion de déploiements à grande échelle, nous avons développé un cadre de maintenance complet qui couvre les aspects à la fois techniques et opérationnels.
Protocole de maintenance technique
- Réindexation hebdomadaire de la base de données vectorielle pour des performances optimales
- Itérations d'affinage mensuelles avec des jeux de données sélectionnés
- Vérifications automatisées de la fraîcheur des données (mise en place de politiques TTL)
- Évaluation régulière des performances par rapport aux indicateurs clés :some text
- Latence des requêtes (cible < 200 ms)
- Exactitude de la récupération (maintien > 95 %)
- Disponibilité du système (atteinte de 99,99 %)
Gestion de la qualité des données :
- Pipelines automatisés de validation des contenus
- Vérifications syntaxiques et sémantiques régulières
- Contrôle de version pour toutes les sources de connaissances
- Algorithmes de détection de dérive pour repérer les informations obsolètes
- Déduplication des contenus avec une exactitude de 99,7 %
Notre implémentation RAG inclut un monitoring continu des schémas de récupération, signalant automatiquement les anomalies et les lacunes potentielles d'information.
Cette approche proactive a réduit la dégradation du système de 76 % par rapport aux stratégies de maintenance réactives.
Un défi facile à sous-estimer est la précision de la récupération à grande échelle, et plus précisément le rapport signal sur bruit.
Dans notre étude de référence, lorsqu'on a interrogé Claude avec des MCP sur les réalisations d'une personne précise, il a récupéré 10 contacts sans rapport dans le CRM.
Le rapport signal sur bruit s'est dégradé à mesure que le nombre de sources augmentait, soit l'inverse de ce que l'on recherche. Un système de récupération dédié évite cela car la logique d'orchestration préexiste au lieu d'être improvisée par le modèle au moment de l'inférence, à chaque requête. Le classement Agentic Tool Use de Scale AI et le cadre CLASSic d'Aisera évaluent tous deux les agents IA sur des tâches multi-outils, et tous deux constatent que l'exactitude se dégrade à mesure que le nombre d'outils augmente.
Conclusion
L'évolution des bases de connaissances LLM représente un changement de paradigme dans la façon dont les organisations gèrent et exploitent leur savoir collectif.
Notre parcours d'implémentation a révélé que le succès tient non seulement à la technologie, mais aussi à l'intégration réfléchie des capacités d'IA avec l'expertise humaine.
Lorsque vous évaluez votre stack de connaissances IA, la question qui vaut la peine d'être posée n'est pas « quel modèle devrions-nous utiliser ? » mais « comment la récupération est-elle architecturée ? »
Le modèle est de plus en plus banalisé. C'est dans la couche de récupération que se joue la variance.
À mesure que ces systèmes continuent de mûrir, nous observons une trajectoire claire vers des solutions de gestion des connaissances plus intelligentes, plus adaptatives et plus efficaces, qui transformeront en profondeur la façon dont les organisations fonctionnent et font évoluer leurs bases de connaissances.
FAQ
Quelle est la meilleure façon de structurer nos données et de garantir des réponses exactes pour les employés ?
Dans une application comme Slite, on structure ses connaissances via les Canaux, qui sont les sections de premier niveau de votre espace de travail. Voyez-les comme des dossiers. La hiérarchie des contenus est la suivante : Canaux > Docs > Sous-docs.
Bonnes pratiques : commencez simple. Cartographiez d'abord vos contenus et votre audience. Le recoupement entre les deux constitue le plan directeur de vos canaux. Visez un maximum de 10 docs de premier niveau par canal. Créez une page d'accueil pour chaque canal à l'aide de la commande IA /générer un répertoire.
Comment éviter les réponses erronées ?
Dans le cas de Slite Agent, la recherche sémantique fonctionne sur l'ensemble de vos outils connectés (docs, Slack, tâches, tickets) et génère des réponses accompagnées de citations indiquant exactement d'où provient chaque élément. Elle utilise le RAG (Retrieval Augmented Generation) et respecte les permissions existantes, de sorte que les utilisateurs ne voient que des réponses issues de sources auxquelles ils sont autorisés à accéder. Les docs vérifiés sont mieux classés dans les résultats ; les docs obsolètes sont exclus, de sorte que la qualité des réponses s'améliore à mesure que votre base de connaissances s'améliore. La vue d'ensemble « Ask Insights » montre aux administrateurs quelles questions sont restées sans réponse ou ont été signalées comme erronées, afin que vous sachiez exactement quel contenu créer ensuite.
Peut-on faire confiance à une base de connaissances LLM avec de la documentation interne ?
La sécurité de la base de connaissances et la confiance sont souvent les premières préoccupations lorsqu'on introduit l'IA dans le travail quotidien. La bonne nouvelle, c'est que l'IA moderne, prête pour l'entreprise, est conçue en gardant à l'esprit la protection des données, à condition de choisir la bonne plateforme.
Est-il sûr d'utiliser les données de l'entreprise avec OpenAI ?
Oui, si vous utilisez les versions professionnelles (Enterprise) du service. À partir du moment où vous payez le service, vous pouvez vous désinscrire des comportements et des parties du service considérés comme risqués : l'utilisation de vos données pour entraîner les modèles, la propriété des données, les normes de sécurité et les contrôles de rétention des données. Toute entreprise qui cherche à vous vendre un logiciel ou un service d'IA devrait répondre pleinement à ces exigences de sécurité.
Comment garder les informations sensibles confidentielles ?
Pour les utilisateurs de Slite qui utilisent aussi Slite Agent, il ne fait remonter que les informations qu'un utilisateur est déjà autorisé à voir. Il respecte les rôles, les règles d'accès et les permissions de dossiers existants sur tous les outils connectés, donc il ne crée pas de nouveaux risques de sécurité ; il rend simplement les informations autorisées plus faciles à trouver. Chaque réponse s'accompagne de citations renvoyant à la source d'origine, de sorte que rien ne ressemble à une boîte noire. Les utilisateurs peuvent vérifier l'exactitude, et le système de vérification de Slite maintient à jour et approuvé le contenu sur lequel l'IA s'appuie.

