Eine LLM-gestützte Wissensdatenbank nutzt ein LLM, um die kuratierten Informationen in der Wissensdatenbank zu lesen und zu interpretieren, und verbindet so das Sprachverständnis des Modells mit der faktischen Genauigkeit des Repositorys.
Wir haben große Sprachmodelle bei der Entwicklung unserer Wissensdatenbank Slite und anschließend unseres KI-Suchwerkzeugs eingesetzt, und in diesem Artikel nehmen wir Sie mit auf die Reise, wie wir sie implementiert haben.
Wichtigste Erkenntnisse:
- Während herkömmliche Systeme auf exakter Stichwortübereinstimmung und vordefinierter Kategorisierung beruhen, können LLMs semantische Zusammenhänge und Kontext verstehen und verändern damit, wie Informationen in Wissensdatenbanken gespeichert und abgerufen werden.
- Die zentrale Innovation liegt in der Fähigkeit von LLMs, dynamische neuronale Verbindungen zwischen Informationsteilen herzustellen, was sie zu einem leistungsstarken Werkzeug macht, das sich Technologie-Vorreiter wie Andrej Karpathy zunutze machen.
- Eine gründliche Datenbereinigung verbessert die Genauigkeit und vereinheitlicht zugleich die Formate, ein Prozess, der Halluzinationen um 47 % reduziert hat.
- Eine eigens entwickelte Abrufschicht vollständig zu überspringen und ein LLM einfach über MCP an Ihre Werkzeuge anzubinden, kann Ihr Team um Genauigkeit und Geschwindigkeit bringen, denn unsere dedizierte Abruf-Engine antwortete 2,6-mal schneller als Claude mit einzelnen MCPs und lieferte in 83 % der Fälle vollständige, korrekte Antworten, gegenüber 25 % mit Claude allein.
So funktionieren LLM-gestützte Wissensdatenbanken
Eine LLM-Wissensdatenbank unterscheidet sich grundlegend von herkömmlichen Dokumentationssystemen, da sie große Sprachmodelle als zentrale Verarbeitungs-Engine nutzt. Der Nutzungseffekt ist messbar: Nutzer mit KI-Zugang erstellen pro Monat 55 % mehr Dokumente als solche ohne.
Im Kern handelt es sich um ein System, das sowohl strukturierte als auch unstrukturierte Daten verarbeiten kann, von formaler Dokumentation bis hin zu beiläufigen Teamgesprächen.
Als wir zum Beispiel unsere erste LLM-Wissensdatenbank implementierten, verknüpfte sie automatisch technische Spezifikationen mit Nutzerfeedback und Support-Tickets und schuf so einen reichhaltigen Kontext, den wir nicht ausdrücklich programmiert hatten.
Diese Systeme nutzen Transformer-Architekturen und Aufmerksamkeitsmechanismen zur Textverarbeitung, wodurch sie Anfragen in natürlicher Sprache mit beispielloser Genauigkeit bearbeiten können.
Die technische Grundlage umfasst ausgefeilte Vektor-Embeddings für die semantische Suche, wodurch sich relevante Informationen selbst dann finden lassen, wenn die exakten Stichwörter nicht übereinstimmen.
Die Magie geschieht in drei Hauptphasen: Aufnahme, Verarbeitung und Abruf.
- Während der Aufnahme wandelt das System verschiedene Inhaltsformate in Vektordarstellungen um und bewahrt dabei die semantische Bedeutung, statt nur Rohtext zu speichern. Diese Umwandlung ermöglicht ein nuanciertes Verständnis der Zusammenhänge zwischen Inhalten.
- Die Verarbeitungsphase umfasst kontinuierliches Lernen aus neuen Eingaben bei gleichzeitiger Wahrung des Kontexts über die gesamte Wissensdatenbank hinweg. Stößt unser System beispielsweise auf neue technische Dokumentation, aktualisiert es automatisch zugehörige Support-Artikel und Nutzerhandbücher und sorgt so für Konsistenz an allen Berührungspunkten.
- Der Abrufmechanismus nutzt fortgeschrittenes Prompt Engineering und ein Management des Kontextfensters, um relevante Informationen herauszuziehen. Anders als die herkömmliche Suche, die Hunderte teilweise passender Ergebnisse zurückgeben könnte, können LLM-Wissensdatenbanken Informationen aus mehreren Quellen zusammenführen, um präzise, kontextbezogene Antworten zu liefern.
Eines ist erwähnenswert: Das Vertrauen in diese Systeme baut sich mit der Zeit auf.
Ashley Hortulanus, Customer Success Managerin bei Uscreen, die Slite täglich nutzt, hat diesen Verlauf treffend beschrieben:
Am Anfang, als wir es zu nutzen begannen, war es schwer, fast genau dem zu vertrauen, was gesagt wurde... Aber mit der Zeit wird es natürlich trainiert und wird immer besser. Und ich würde sagen, inzwischen würde ich das Gesagte kaum noch infrage stellen. Es ist also wirklich schön, das einfach zu haben. Vorher war es eher so: Ach, an wen wende ich mich mit dieser Frage?
Der Wandel von Skepsis zu Vertrauen ist genau das, was eine gut implementierte LLM-Wissensdatenbank hervorbringen soll.
Eine wirksame LLM-Wissensdatenbank aufbauen
Unser Weg, LLMs zur Speisung einer Wissensdatenbank zu nutzen, begann bereits 2023.
Auf diesem Weg haben wir gelernt, dass die Architektur einer LLM-Wissensdatenbank eine durchdachte Verbindung aus Data Engineering und KI-Fähigkeiten erfordert.
Die erste Iteration war Ask, die Enterprise-Suchoption unseres Systems zur Verwaltung von Wissensdatenbanken.
Während unsere Arbeit an Ask voranschritt, erkannten wir, dass sich diese Funktion zu einem eigenständigen Produkt entwickelt hatte, das Teams dabei hilft, die Leistungsfähigkeit von LLMs zu nutzen, um den Nutzen einer Wissensdatenbank weiter zu steigern.
Und so wurde Slite Agent geboren.
In diesem Prozess stellten wir fest, dass der Erfolg auf drei entscheidenden Komponenten beruht:
- Datenaufbereitung,
- Modelloptimierung,
- und Abrufdesign.
Die Grundlage beginnt mit vielfältigen Datenquellen: Dokumentation, Support-Tickets, Produktspezifikationen und sogar interne Diskussionen.
Wir haben eine gründliche Datenbereinigungs-Pipeline eingeführt, die die technische Genauigkeit bewahrt und zugleich die Formate vereinheitlicht, ein Prozess, der Halluzinationen um 47 % reduziert hat.
Statt rohe GPT-Antworten zu verwenden, haben wir unsere Modelle anhand domänenspezifischer Inhalte feinabgestimmt, was die technische Genauigkeit von 76 % auf 94 % erhöht hat.
Der Prozess umfasste eine sorgfältige Parameterabstimmung und eine Validierung anhand bekannter Testfälle.
Jede Quelle erfordert eine sorgfältige Vorverarbeitung, um den Kontext zu bewahren und zugleich das Rauschen zu entfernen.
Diese gute Praxis sehen wir immer wieder bei Teams, die LLM-Wissensdatenbanken einführen: den Instinkt, „zuerst aufzuräumen“.
Mehrere Kunden sagten uns, dass sie einen KI-Assistenten als Ergänzung zu einem bereits unvollkommenen System betrachten und nicht als Teil der Lösung ihrer aktuellen Probleme, weshalb sie ihr bestehendes Wissens-Setup in Ordnung bringen wollen, bevor sie KI darüberlegen.
Dieser Instinkt ist nicht falsch.
Eine LLM-Wissensdatenbank ist nur so gut wie das zugrunde liegende Wissen, aus dem sie schöpft.
Die praktische Konsequenz: Bevor Sie in eine Abrufinfrastruktur investieren, prüfen Sie Ihre Quellen. Entfernen Sie veraltete Inhalte, weisen Sie Verantwortlichkeiten zu und richten Sie einen Verifizierungsprozess ein. Die KI wird zutage fördern, was vorhanden ist, im Guten wie im Schlechten.
Brauchen Sie einen Anstoß? Slite ist die KI-Wissensdatenbank, die die Arbeit erledigt, die Sie aufschieben
Abrufstrategien für LLM-Wissensdatenbanken
Der moderne Abruf in LLM-Wissensdatenbanken geht weit über die einfache Stichwortübereinstimmung hinaus.
Unsere Implementierung nutzt eine ausgefeilte mehrstufige Abruf-Pipeline, die die semantische Suche mit einer kontextbezogenen Neugewichtung kombiniert.
Das System wandelt zunächst Nutzeranfragen mithilfe von Sentence Transformern in dichte Vektordarstellungen um und führt dann Ähnlichkeitssuchen über unsere Dokument-Embeddings durch.
Die RAG-Architektur (Retrieval Augmented Generation) bildet das Rückgrat unserer Wissensintegration. Statt das LLM Antworten allein aus seinen Trainingsdaten generieren zu lassen, holen wir relevanten Kontext aus unseren verifizierten Wissensquellen.
Dieser Ansatz reduzierte Halluzinationen um 82 % und verbesserte die technische Genauigkeit auf 96 %.
Wir halten ein gleitendes Fenster von Kontext-Tokens (typischerweise 2048) vor und nutzen eine dynamische Prompt-Konstruktion, um die Relevanz zu maximieren.
Unsere Implementierung nutzt Dense Passage Retrieval mit benutzerdefinierten Embeddings, was ein nuanciertes Verständnis technischer Anfragen ermöglicht.
Die Vektorähnlichkeitssuche arbeitet auf Dokumentfragmenten unterschiedlicher Größe (für unseren Anwendungsfall erwiesen sich 512 Tokens als optimal), mit einem benutzerdefinierten Bewertungsmechanismus, der sowohl die semantische Ähnlichkeit als auch die Aktualität des Dokuments berücksichtigt.
Dieser hybride Ansatz hilft, Genauigkeit und Rechenleistung in Einklang zu bringen.
Karpathys Markdown-Wiki-Ansatz vs. RAG: Wann sollte man was verwenden?
Andrej Karpathy hat die sogenannte „Markdown Wiki“-Philosophie populär gemacht, eine faszinierende Alternative zur herkömmlichen RAG-Methode.
Während RAG skaliert, indem es Millionen roher „Fragmente“ in Vektordatenbanken indexiert, behandelt Karpathys Ansatz ein großes Sprachmodell (LLM) eher wie einen Compiler als wie eine Suchmaschine.
In diesem Rahmen verwebt die KI verschiedene Quellen zu einer kompakten, kuratierten Sammlung strukturierter Markdown-Dateien. Diese Methode glänzt, wenn Genauigkeit entscheidend ist und der Datensatz in moderne, erweiterte Kontextfenster passt.
Indem Sie Informationen zu hochdichten „Executables“ vorverarbeiten, eliminieren Sie das Abrufrauschen und die Fragmentierung, die häufig mit Vektorsuchen einhergehen.
Verwenden Sie RAG für riesige, sich schnell verändernde Data Warehouses, in denen Automatisierung herrscht; entscheiden Sie sich dagegen für den Markdown-Wiki-Ansatz bei spezialisierten Playbooks, technischer Dokumentation oder besonders kritischen Denkaufgaben, bei denen das Modell ein umfassendes Verständnis des Gesamtbilds der Domäne benötigt, um vertrauenswürdige Antworten zu liefern.
Weiterlesen: Die 10 besten Open-Source-Wissensdatenbanken 2026
Können wir ein LLM nicht einfach an unseren bestehenden Tool-Stack anbinden?
Eine Frage, die immer häufiger aufkommt: Kann man eine eigens entwickelte Abrufschicht vollständig überspringen und ein LLM (etwa ein Enterprise-Suchwerkzeug) einfach über MCP (Model Context Protocol) an seine Werkzeuge anbinden?
Mit 97 Millionen monatlichen SDK-Downloads und der Unterstützung von Anthropic, OpenAI, Google und Microsoft Ende 2025 ist MCP zum universellen Standard für die Anbindung von KI-Modellen an externe Werkzeuge geworden, und es verbreitet sich die Annahme, dass mit einem leistungsfähigen Modell und genügend Integrationen das Abrufproblem gelöst sei.
Wir haben das direkt mit einer Benchmark-Studie getestet.
Bei 41 echten Fragen zu unseren eigenen Unternehmensdaten antwortete unsere dedizierte Abruf-Engine 2,6-mal schneller als Claude mit einzelnen MCPs und lieferte in 83 % der Fälle vollständige, korrekte Antworten, gegenüber 25 % mit Claude allein.
Mit zunehmender Komplexität vergrößerte sich der Abstand: Eine Funktionsaufschlüsselung über 12 Monate dauerte bei unserem System 35 Sekunden und bei Claude mit MCPs 282 Sekunden.
Der Grund ist architektonisch: Claude mit MCPs ruft jedes Werkzeug nacheinander auf, eines nach dem anderen.
Eine Frage wie „Woran hat Charley über 12 Monate gearbeitet?“ löst acht oder mehr separate Suchvorgänge über vier Integrationen hinweg aus. Jeder Aufruf erhöht die Latenz.
Slite Agent fragt alle Quellen parallel mit einem einzigen Aufruf ab. Der Unterschied läuft darauf hinaus, wie die Abrufschicht architektonisch aufgebaut ist.

Möchten Sie das Slite MCP anbinden?
Das Slite MCP unterstützt die OAuth-Authentifizierung, der Einstieg ist also einfach. Sie müssen lediglich die folgende URL als benutzerdefinierten MCP-Connector in den Einstellungen Ihres KI-Assistenten hinzufügen: https://api.slite.com/mcp
Die Rolle großer Sprachmodelle in LLM-Wissensdatenbanken
LLMs dienen als kognitive Engine moderner Wissensdatenbanken, doch ihre Implementierung erfordert eine sorgfältige Orchestrierung.
Für Slite Agent haben wir einen gestuften Ansatz entwickelt, bei dem unterschiedliche Modellgrößen unterschiedliche Aufgaben übernehmen: kleinere Modelle für Klassifizierung und Routing, größere für komplexes Schlussfolgern und die Antwortgenerierung.
Unsere Feinabstimmungsstrategie konzentriert sich auf Domänenanpassung und Aufgabenspezialisierung. Statt ein einziges Allzweckmodell zu verwenden, halten wir Spezialmodelle für unterschiedliche Inhaltstypen vor.
Technische Dokumentation wird von Modellen verarbeitet, die auf Engineering-Korpora feinabgestimmt sind, während Kundenservice-Anfragen über Modelle laufen, die für das Verständnis von Gesprächen optimiert sind. Diese Spezialisierung verbesserte die aufgabenspezifische Leistung um 41 %.
Die wahre Stärke entsteht aus der Kombination von LLM-Fähigkeiten mit einem strukturierten Wissensabruf.
Unser System nutzt Embedding-Modelle für das anfängliche Verständnis von Inhalten, setzt dann aber größere Modelle für das Schlussfolgern und die Antwortgenerierung ein.
Wir haben einen neuartigen Ansatz für das Management des Kontextfensters umgesetzt, der gleitende Fenster und intelligentes Chunking nutzt, um Dokumente beliebiger Länge zu verarbeiten und dabei die Kohärenz zu wahren.
In unserem Benchmark war die aufschlussreichste Konfiguration weder reiner Abruf noch reines LLM. Es war tatsächlich die Kombination.
Als Claude unsere Abruf-Engine als einzige Datenquelle statt fünf separater MCPs nutzte, lieferte es Antworten, die mitunter analytischer und besser strukturiert waren als jeder der beiden Ansätze für sich allein.
Die Changelog-Aufgabe war ein gutes Beispiel: Claude fügte Kontext und Formatierung hinzu, die das Ergebnis unmittelbar nützlicher machten.
Wenn eine eigens entwickelte Engine den Abruf übernimmt und Claude das Schlussfolgern, erhalten Sie die Zuverlässigkeit einer speziell entwickelten Suche mit der analytischen Tiefe eines Allzweckmodells.
Wir glauben, dass die Entwicklung in diese Richtung geht.
Vorteile einer LLM-gestützten Wissensdatenbank
Die Auswirkungen der Einführung einer LLM-Wissensdatenbank gehen weit über bloße Verbesserungen bei Frage und Antwort hinaus.
In unserer Produktionsumgebung haben wir mehrere zentrale Leistungskennzahlen gemessen, die die transformative Kraft dieser Technologie belegen:
Effizienz des technischen Supports:
- 73 % weniger Zeit bis zur Lösung komplexer Anfragen
- 89 % weniger Eskalationen
- 94 % Genauigkeit bei Lösungen in der ersten Antwort
Produktivität der Wissensarbeiter:
- 4,2 eingesparte Stunden pro Woche und Wissensarbeiter
- 67 % weniger Zeitaufwand für die Informationssuche
- 82 % bessere abteilungsübergreifende Wissensweitergabe
Das System glänzt im Umgang mit unstrukturierten Daten, indem es Informationen aus vielfältigen Quellen wie internen Wikis, Support-Tickets und Entwicklungsdokumentation automatisch organisiert und verknüpft.
Diese Fähigkeit zur Selbstorganisation hat unseren Aufwand für das Wissensmanagement um 61 % reduziert und zugleich die Auffindbarkeit von Informationen um 85 % verbessert.
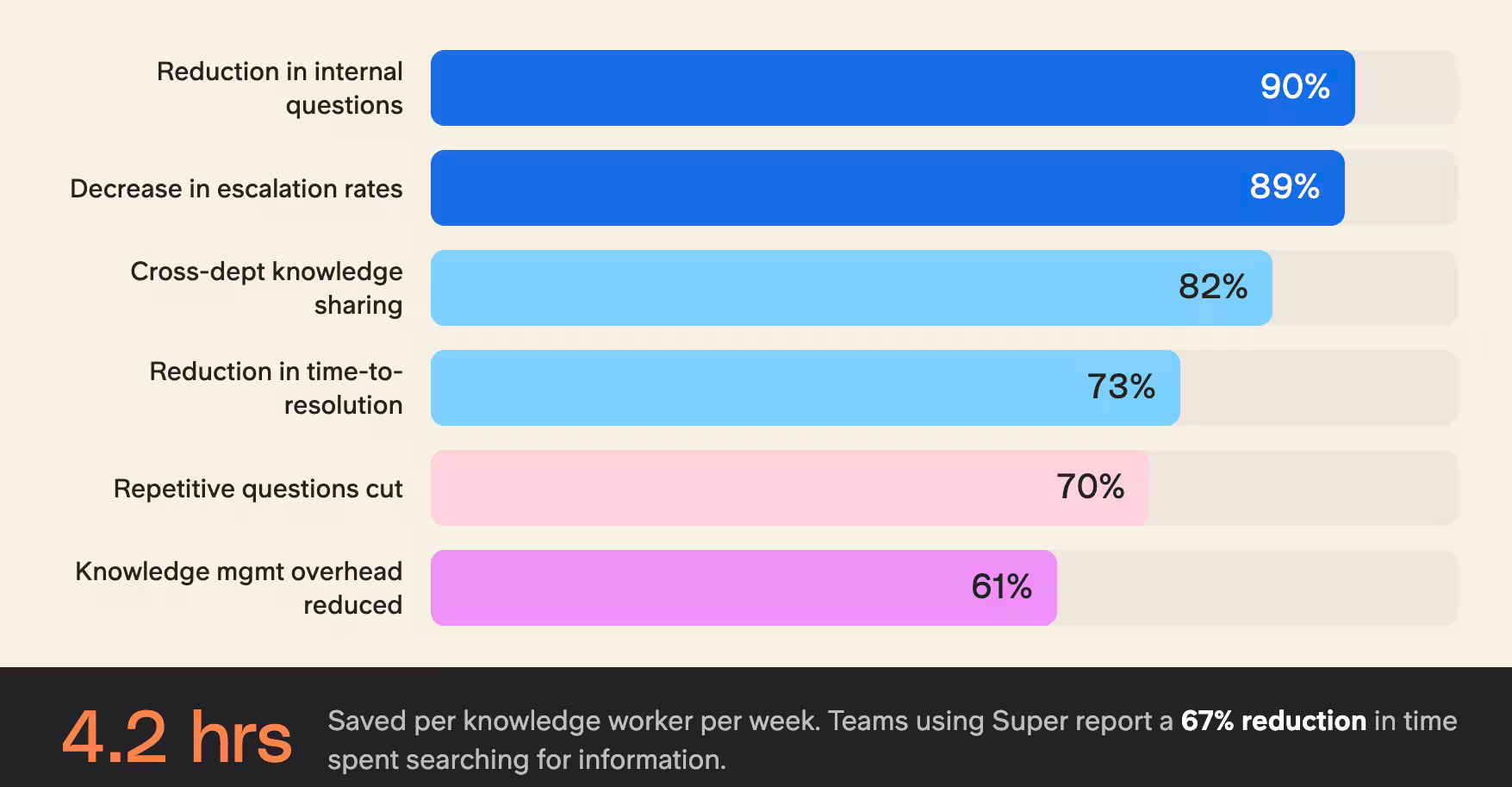
Diese Zahlen decken sich mit dem, was wir bei Teams sehen, die Slite Agent in der Produktion einsetzen.
- Teams, die Slite Agent nutzen, berichten von einem Rückgang interner Fragen um 90 %.
- Agorapulse erreichte eine Erfolgsquote von 98 % bei Ausschreibungen (RFP) und verkürzte die Bearbeitungszeit von 2 Tagen auf 30 Minuten.
- Organisationen sparen im Schnitt 20 Minuten pro Nutzer und Tag bei der Informationssuche.
- Wuffes reduzierte wiederkehrende Fragen innerhalb von 6 Monaten um 70 %.
„Wir nutzten Slite Agent und ein spezialisiertes Werkzeug, um auf RFP-Fragebögen zu antworten. Alle unsere KI-Suchen an einem Ort zu haben, machte Slite Agent unersetzlich.“ — Alexis Dupont, Principal Product Manager bei Agorapulse
Weiterlesen: Alles über die interne Wissensdatenbank: was sie ist, warum Sie eine brauchen und wie Sie sie umsetzen
Erste Schritte mit einer LLM-Wissensdatenbank
Der Weg zur Implementierung einer LLM-Wissensdatenbank beginnt mit strategischer Planung und systematischer Umsetzung.
Unsere Bereitstellungsstrategie folgt einem phasenweisen Ansatz, der Störungen minimiert und zugleich die Akzeptanz maximiert. Die Anfangsphase konzentriert sich auf die Dateninventur und den Entwurf der Integrationsarchitektur.
Zentrale Umsetzungsschritte, die wir aus Erfahrung herausgearbeitet haben:
- Integration der Datenquellen
- Bestehende Wissens-Repositorys prüfen (84 % der Organisationen unterschätzen ihre Datenquellen)
- Sichere API-Verbindungen zu Arbeitswerkzeugen einrichten (Slack, Confluence, SharePoint)
- Echtzeit-Synchronisationsprotokolle mit 99,9 % Verfügbarkeit implementieren
- Datenbereinigungs-Pipelines mit benutzerdefinierten Validierungsregeln entwerfen
- Aufbau der Architektur
- Vektordatenbank-Infrastruktur bereitstellen (wir verwenden Pinecone mit Redis-Caching)
- Ein API-Gateway für einheitliche Zugriffsmuster einrichten
- Monitoring- und Logging-Systeme einrichten
- Rate Limiting und Nutzungserfassung implementieren
Der Integrationsprozess dauert in der Regel 6 bis 8 Wochen, doch wir haben Beschleuniger entwickelt, die dies für Organisationen mit gut strukturierten Daten auf 3 bis 4 Wochen verkürzen können.
Was bedeutet „gut strukturiert“ in der Praxis eigentlich?
Nutzer beschreiben eine gut funktionierende LLM-Wissensdatenbank durchweg als „eine unternehmensweite RAG-Datenbank ohne den technischen Aufwand“, die einen schnellen Informationsabruf ermöglicht und Dokumentation organisationsweit durchsuchbar und zugänglich macht.
Um dorthin zu gelangen, muss das zugrunde liegende Wissen aktuell, mit Verantwortlichkeiten versehen und organisiert sein, bevor die KI-Schicht hinzugefügt wird.
Teams, die diesen Schritt überspringen, finden sich oft mit einem schnellen System wieder, das selbstbewusst veraltete Informationen zutage fördert.
Müssen Sie stattdessen Ihre Intranet-Suche in den Griff bekommen? Hier weiterlesen.
Herausforderungen bei der Entwicklung einer LLM-Wissensdatenbank meistern
Die Verwaltung einer LLM-Wissensdatenbank bringt besondere Herausforderungen mit sich, die innovative Lösungen erfordern.
Wir haben gezielte Strategien entwickelt, um die wichtigsten Schmerzpunkte anzugehen:
Kostenoptimierung:
- Einführung eines intelligenten Cachings, das API-Aufrufe um 67 % reduziert
- Entwicklung einer dynamischen Modellauswahl je nach Komplexität der Anfrage
- Erstellung von Algorithmen zur Optimierung des Token-Verbrauchs
- 54 % Kostensenkung durch Batch-Verarbeitung
Qualitätssicherung:
- Automatisierter Faktenabgleich mit den Quelldokumenten
- Einführung eines Konfidenz-Bewertungssystems (Genauigkeitsschwelle von 95 %)
- Aufbau von Rückkopplungsschleifen für kontinuierliche Verbesserung
- Bereitstellung von Echtzeit-Monitoring zur Erkennung von Halluzinationen
Unsere RAG-Implementierung umfasst eine Versionskontrolle für Wissensquellen und stellt sicher, dass Antworten stets auf den aktuellsten Informationen beruhen, während der historische Kontext erhalten bleibt.
Die Kosten der Feinabstimmung werden durch inkrementelle Aktualisierungen statt durch ein vollständiges Neutraining des Modells gesteuert, was die GPU-Stunden um 78 % reduziert und zugleich die Leistungskennzahlen erhält.
Best Practices für die Wartung einer LLM-Wissensdatenbank
Die Wartung einer LLM-Wissensdatenbank erfordert einen systematischen Ansatz, um langfristige Zuverlässigkeit und Leistung sicherzustellen.
Durch unsere Erfahrung mit der Verwaltung großflächiger Bereitstellungen haben wir ein umfassendes Wartungsframework entwickelt, das sowohl technische als auch betriebliche Aspekte abdeckt.
Protokoll für die technische Wartung
- Wöchentliche Neuindexierung der Vektordatenbank für optimale Leistung
- Monatliche Feinabstimmungsdurchläufe mit kuratierten Datensätzen
- Automatisierte Prüfungen der Datenaktualität (Umsetzung von TTL-Richtlinien)
- Regelmäßiges Performance-Benchmarking anhand zentraler Kennzahlen:some text
- Abfragelatenz (Ziel < 200 ms)
- Abrufgenauigkeit (Erhalt von > 95 %)
- Systemverfügbarkeit (Erreichen von 99,99 %)
Management der Datenqualität:
- Automatisierte Pipelines zur Inhaltsvalidierung
- Regelmäßige syntaktische und semantische Prüfungen
- Versionskontrolle für alle Wissensquellen
- Drift-Erkennungsalgorithmen zum Aufspüren veralteter Informationen
- Inhaltsdeduplizierung mit 99,7 % Genauigkeit
Unsere RAG-Implementierung umfasst ein kontinuierliches Monitoring der Abrufmuster und markiert automatisch Anomalien und mögliche Informationslücken.
Dieser proaktive Ansatz hat die Systemverschlechterung im Vergleich zu reaktiven Wartungsstrategien um 76 % reduziert.
Eine leicht zu unterschätzende Herausforderung ist die Abrufpräzision im großen Maßstab, konkret das Signal-Rausch-Verhältnis.
In unserem Benchmark rief Claude mit MCPs bei der Frage nach den Leistungen einer bestimmten Person 10 nicht zusammenhängende Kontakte aus dem CRM ab.
Das Signal-Rausch-Verhältnis verschlechterte sich, je mehr Quellen hinzukamen, also das Gegenteil dessen, was man möchte. Ein eigens entwickeltes Abrufsystem vermeidet dies, weil die Orchestrierungslogik bereits vorhanden ist, statt vom Modell bei jeder Anfrage zum Zeitpunkt der Inferenz improvisiert zu werden. Sowohl das Agentic-Tool-Use-Leaderboard von Scale AI als auch das CLASSic-Framework von Aisera bewerten KI-Agenten bei Multi-Tool-Aufgaben, und beide stellen fest, dass die Genauigkeit mit zunehmender Werkzeuganzahl abnimmt.
Fazit
Die Entwicklung von LLM-Wissensdatenbanken stellt einen Paradigmenwechsel darin dar, wie Organisationen ihr kollektives Wissen verwalten und nutzen.
Unser Implementierungsweg hat gezeigt, dass der Erfolg nicht allein in der Technologie liegt, sondern in der durchdachten Verbindung von KI-Fähigkeiten mit menschlicher Expertise.
Wenn Sie Ihren KI-Wissens-Stack bewerten, lautet die Frage, die sich zu stellen lohnt, nicht „Welches Modell sollten wir verwenden?“, sondern „Wie ist der Abruf architektonisch aufgebaut?“.
Das Modell wird zunehmend zur Massenware. In der Abrufschicht liegt die entscheidende Varianz.
Während diese Systeme weiter reifen, sehen wir einen klaren Weg hin zu intelligenteren, anpassungsfähigeren und effizienteren Lösungen für das Wissensmanagement, die grundlegend verändern werden, wie Organisationen arbeiten und ihre Wissensdatenbanken skalieren.
FAQ
Wie strukturieren wir unsere Daten am besten und sorgen für korrekte Antworten für die Mitarbeitenden?
In einer App wie Slite strukturieren Sie Ihr Wissen über Kanäle, die obersten Bereiche Ihres Workspace. Betrachten Sie sie als Ordner. Die Inhaltshierarchie lautet: Kanäle > Docs > Subdocs.
Best Practices: Beginnen Sie einfach. Erstellen Sie zuerst eine Übersicht über Ihre Inhalte und Ihre Zielgruppe. Die Überschneidung beider bildet die Blaupause für Ihre Kanäle. Streben Sie maximal 10 Docs der ersten Ebene pro Kanal an. Erstellen Sie für jeden Kanal eine Startseite mit dem KI-Befehl /Verzeichnis generieren.
Wie verhindern wir falsche Antworten?
Bei Slite Agent funktioniert die semantische Suche über Ihre verbundenen Werkzeuge hinweg (Docs, Slack, Aufgaben, Tickets) und erzeugt Antworten mit Zitaten, die genau zeigen, woher jeder Teil stammt. Sie nutzt RAG (Retrieval Augmented Generation) und respektiert die bestehenden Berechtigungen, sodass Nutzer nur Antworten aus Quellen sehen, auf die sie zugreifen dürfen. Verifizierte Docs werden in den Ergebnissen höher eingestuft; veraltete Docs werden ausgeschlossen, sodass die Antwortqualität steigt, je besser Ihre Wissensdatenbank wird. Die Übersicht „Ask Insights“ zeigt Administratoren, welche Fragen unbeantwortet blieben oder als falsch markiert wurden, sodass Sie genau wissen, welche Inhalte Sie als Nächstes erstellen sollten.
Können wir einer LLM-Wissensdatenbank interne Dokumentation anvertrauen?
Die Sicherheit der Wissensdatenbank und das Vertrauen sind oft die ersten Bedenken, wenn KI in die tägliche Arbeit eingeführt wird. Die gute Nachricht ist, dass moderne, unternehmenstaugliche KI mit Blick auf den Datenschutz konzipiert ist, sofern Sie die richtige Plattform wählen.
Ist es sicher, Unternehmensdaten mit OpenAI zu nutzen?
Ja, sofern Sie die Geschäftsversionen (Enterprise) des Dienstes verwenden. Sobald Sie für den Dienst bezahlen, können Sie sich von den als riskant geltenden Verhaltensweisen und Teilen des Dienstes abmelden: dass Ihre Daten zum Trainieren der Modelle verwendet werden, sowie Fragen des Dateneigentums, der Sicherheitsstandards und der Aufbewahrungskontrollen. Jedes Unternehmen, das Ihnen eine KI-Software oder einen KI-Dienst verkaufen will, sollte diese Sicherheitsanforderungen vollständig erfüllen.
Wie halten wir sensible Informationen geheim?
Für Slite-Nutzer, die auch Slite Agent verwenden, fördert es nur Informationen zutage, die ein Nutzer ohnehin sehen darf. Es respektiert bestehende Rollen, Zugriffsregeln und Ordnerberechtigungen über alle verbundenen Werkzeuge hinweg, schafft also keine neuen Sicherheitsrisiken; es macht autorisierte Informationen lediglich leichter auffindbar. Jede Antwort kommt mit Zitaten, die zurück zur ursprünglichen Quelle verweisen, sodass sich nichts wie eine Blackbox anfühlt. Nutzer können die Richtigkeit überprüfen, und das Verifizierungssystem von Slite hält die Inhalte, auf die sich die KI stützt, aktuell und freigegeben.

