Una base de conocimiento impulsada por un LLM utiliza un LLM para leer e interpretar la información curada almacenada en la base de conocimiento, combinando la comprensión del lenguaje del modelo con la exactitud factual del repositorio.
Hemos aplicado grandes modelos de lenguaje durante el desarrollo de nuestra base de conocimiento, Slite, y posteriormente de nuestra herramienta de búsqueda con IA, y a lo largo de este artículo te llevamos por el recorrido de cómo los implementamos.
Conclusiones clave:
- Mientras que los sistemas convencionales dependen de la coincidencia exacta de palabras clave y de una categorización predefinida, los LLM pueden comprender relaciones semánticas y contexto de formas que transforman cómo se almacena y se recupera la información en las bases de conocimiento.
- La innovación clave reside en la capacidad de los LLM de formar conexiones neuronales dinámicas entre piezas de información, lo que lo convierte en una herramienta potente que innovadores tecnológicos como Andrej Karpathy aprovechan a su favor.
- Una limpieza rigurosa de los datos mejora la exactitud al mismo tiempo que estandariza los formatos, un proceso que redujo las alucinaciones en un 47 %.
- Saltarse por completo una capa de recuperación diseñada para tal fin y limitarse a conectar un LLM a tus herramientas mediante MCP puede privar a tu equipo de exactitud y velocidad, ya que nuestro motor de recuperación dedicado respondió 2,6 veces más rápido que Claude con MCP individuales, y dio respuestas completas y exactas el 83 % de las veces frente al 25 % con Claude por sí solo.
Cómo funcionan las bases de conocimiento impulsadas por un LLM
Una base de conocimiento con LLM difiere fundamentalmente de los sistemas de documentación tradicionales al usar los grandes modelos de lenguaje como motor de procesamiento central. El efecto de uso es medible: los usuarios con acceso a la IA crean un 55 % más de documentos al mes que quienes no lo tienen.
En esencia, es un sistema capaz de procesar tanto datos estructurados como no estructurados, desde documentación formal hasta conversaciones informales del equipo.
Por ejemplo, cuando implementamos nuestra primera base de conocimiento con LLM, vinculó automáticamente las especificaciones técnicas con los comentarios de los usuarios y los tickets de soporte, creando un contexto rico que no habíamos programado de forma explícita.
Estos sistemas usan arquitecturas de transformadores y mecanismos de atención para procesar texto, lo que les permite gestionar consultas en lenguaje natural con una precisión sin precedentes.
La base técnica incluye sofisticados embeddings vectoriales para la búsqueda semántica, lo que hace posible encontrar información relevante incluso cuando las palabras clave exactas no coinciden.
La magia ocurre en tres etapas principales: ingesta, procesamiento y recuperación.
- Durante la ingesta, el sistema convierte diversos formatos de contenido en representaciones vectoriales, conservando el significado semántico en lugar de limitarse a almacenar texto en bruto. Esta transformación permite una comprensión matizada de las relaciones entre contenidos.
- La etapa de procesamiento implica un aprendizaje continuo a partir de nuevas entradas, manteniendo a la vez el contexto en toda la base de conocimiento. Por ejemplo, cuando nuestro sistema encuentra nueva documentación técnica, actualiza automáticamente los artículos de soporte y las guías de usuario relacionados, garantizando la coherencia en todos los puntos de contacto.
- El mecanismo de recuperación utiliza ingeniería de prompts avanzada y una gestión de la ventana de contexto para extraer la información relevante. A diferencia de la búsqueda tradicional, que podría devolver cientos de resultados parcialmente coincidentes, las bases de conocimiento con LLM pueden sintetizar información de múltiples fuentes para ofrecer respuestas precisas y contextuales.
Algo que vale la pena señalar: la confianza en estos sistemas se construye con el tiempo.
Ashley Hortulanus, Customer Success Manager en Uscreen que usa Slite a diario, describió bien esa evolución:
Al principio, cuando empezamos a usarlo, era difícil casi confiar exactamente en lo que se decía... Pero con el tiempo, evidentemente, se va entrenando y va mejorando cada vez más. Y diría que ahora apenas cuestiono lo que se dice. Así que es realmente agradable simplemente disponer de eso. Mientras que antes era como: ah, ¿a quién acudo con esta pregunta?
El paso del escepticismo a la confianza es precisamente lo que una base de conocimiento con LLM bien implementada está diseñada para producir.
Cómo construir una base de conocimiento con LLM eficaz
Nuestro camino hacia el uso de LLM para impulsar una base de conocimiento comenzó en 2023.
A lo largo de ese camino hemos aprendido que la arquitectura de una base de conocimiento con LLM requiere una combinación reflexiva de ingeniería de datos y capacidades de IA.
La primera iteración fue Ask, la opción de búsqueda empresarial de nuestro sistema de gestión de bases de conocimiento.
A medida que avanzábamos con Ask, nos dimos cuenta de que esta función había tomado la forma de un producto independiente para ayudar a los equipos a aprovechar la potencia de los LLM y potenciar aún más los beneficios de una base de conocimiento.
Y así nació Slite Agent.
A lo largo de ese proceso descubrimos que el éxito reside en tres componentes críticos:
- la preparación de los datos,
- la optimización del modelo,
- y el diseño de la recuperación.
La base parte de fuentes de datos diversas: documentación, tickets de soporte, especificaciones de producto e incluso debates internos.
Implementamos un riguroso pipeline de limpieza de datos que conserva la exactitud técnica al tiempo que estandariza los formatos, un proceso que redujo las alucinaciones en un 47 %.
En lugar de usar respuestas de GPT en bruto, ajustamos nuestros modelos con contenido específico de nuestro dominio, lo que elevó la exactitud técnica del 76 % al 94 %.
El proceso implicó un cuidadoso ajuste de parámetros y una validación frente a casos de prueba conocidos.
Cada fuente necesita un preprocesamiento cuidadoso para conservar el contexto a la vez que se elimina el ruido.
Esta buena práctica es algo que hemos visto repetirse en los equipos que adoptan bases de conocimiento con LLM: el instinto de «ordenar primero».
Varios clientes nos dijeron que ven a un asistente de IA como un añadido a un sistema ya imperfecto, no como parte de la solución a sus problemas actuales, así que quieren arreglar su configuración de conocimiento existente antes de añadir una capa de IA por encima.
Este instinto no es erróneo.
Una base de conocimiento con LLM solo es tan buena como el conocimiento subyacente del que se nutre.
La implicación práctica: antes de invertir en infraestructura de recuperación, audita tus fuentes. Elimina el contenido obsoleto, asigna responsabilidades y establece un proceso de verificación. La IA hará aflorar lo que haya, lo bueno y lo malo.
¿Necesitas un empujón? Slite es la base de conocimiento con IA que hace el trabajo que pospones
Estrategias de recuperación para bases de conocimiento con LLM
La recuperación moderna en las bases de conocimiento con LLM va mucho más allá de la simple coincidencia de palabras clave.
Nuestra implementación utiliza un sofisticado pipeline de recuperación de varias etapas que combina la búsqueda semántica con un reordenamiento contextual.
El sistema primero convierte las consultas de los usuarios en representaciones vectoriales densas mediante sentence transformers, y luego realiza búsquedas de similitud en nuestros embeddings de documentos.
La arquitectura RAG (Retrieval Augmented Generation) sirve como columna vertebral de nuestra integración del conocimiento. En lugar de dejar que el LLM genere respuestas únicamente a partir de sus datos de entrenamiento, recuperamos contexto relevante de nuestras fuentes de conocimiento verificadas.
Este enfoque redujo las alucinaciones en un 82 % y mejoró la exactitud técnica hasta el 96 %.
Mantenemos una ventana deslizante de tokens de contexto (normalmente 2048) y usamos una construcción dinámica de prompts para maximizar la relevancia.
Nuestra implementación utiliza recuperación densa de pasajes con embeddings personalizados, lo que permite una comprensión matizada de las consultas técnicas.
La búsqueda de similitud vectorial opera sobre fragmentos de documentos de tamaños variables (descubrimos que 512 tokens eran óptimos para nuestro caso de uso), con un mecanismo de puntuación personalizado que tiene en cuenta tanto la similitud semántica como la frescura del documento.
Este enfoque híbrido ayuda a equilibrar la exactitud con la eficiencia computacional.
El enfoque markdown-wiki de Karpathy frente al RAG: ¿cuándo usar cada uno?
Andrej Karpathy popularizó la llamada filosofía del «Markdown Wiki», una alternativa intrigante al método RAG tradicional.
Mientras que el RAG escala indexando millones de «fragmentos» en bruto en bases de datos vectoriales, el enfoque de Karpathy trata a un gran modelo de lenguaje (LLM) más como un compilador que como un motor de búsqueda.
En este marco, la IA entreteje diversas fuentes en una colección compacta y curada de archivos Markdown estructurados. Este método destaca cuando la exactitud es crucial y el conjunto de datos puede caber dentro de las modernas y ampliadas ventanas de contexto.
Al preprocesar la información en «ejecutables» de alta densidad, eliminas el ruido de recuperación y la fragmentación que a menudo acompañan a las búsquedas vectoriales.
Usa el RAG para vastos almacenes de datos que cambian con rapidez y donde la automatización reina; en cambio, opta por el enfoque Markdown-Wiki para playbooks especializados, documentación técnica o tareas de razonamiento de alto riesgo en las que el modelo necesita una comprensión completa y de «panorama general» del dominio para dar respuestas fiables.
Sigue leyendo: Las 10 mejores bases de conocimiento de código abierto en 2026
¿No podemos simplemente conectar un LLM a nuestro stack de herramientas existente?
Una pregunta que surge cada vez con más frecuencia: ¿puedes saltarte por completo una capa de recuperación diseñada para tal fin y limitarte a conectar un LLM (como una herramienta de búsqueda empresarial) a tus herramientas mediante MCP (Model Context Protocol)?
Con 97 millones de descargas mensuales del SDK y el respaldo de Anthropic, OpenAI, Google y Microsoft a finales de 2025, el MCP se ha convertido en el estándar universal para conectar modelos de IA con herramientas externas, y se está extendiendo la suposición de que, si tienes un modelo capaz y suficientes integraciones, el problema de la recuperación está resuelto.
Probamos esto directamente con un estudio comparativo.
A lo largo de 41 preguntas reales sobre los datos de nuestra propia empresa, nuestro motor de recuperación dedicado respondió 2,6 veces más rápido que Claude con MCP individuales, y dio respuestas completas y exactas el 83 % de las veces frente al 25 % con Claude por sí solo.
La brecha se amplió con la complejidad: un desglose de funcionalidades de 12 meses tardó 35 segundos en nuestro sistema y 282 segundos en Claude con MCP.
La razón es arquitectónica: Claude con MCP llama a cada herramienta de forma secuencial, una tras otra.
Una pregunta como «¿En qué trabajó Charley a lo largo de 12 meses?» desencadena ocho o más búsquedas separadas en cuatro integraciones. Cada llamada añade latencia.
Slite Agent consulta todas las fuentes en paralelo con una sola llamada. La diferencia se reduce a cómo está arquitecturada la capa de recuperación.

¿Quieres conectar el MCP de Slite?
El MCP de Slite admite la autenticación OAuth, así que empezar es fácil. Solo tendrás que añadir la siguiente URL como conector MCP personalizado en los ajustes de tu asistente de IA: https://api.slite.com/mcp
El papel de los grandes modelos de lenguaje en las bases de conocimiento con LLM
Los LLM funcionan como el motor cognitivo de las bases de conocimiento modernas, pero su implementación requiere una orquestación cuidadosa.
Para Slite Agent, hemos desarrollado un enfoque por niveles en el que distintos tamaños de modelo gestionan distintas tareas: modelos más pequeños para la clasificación y el enrutamiento, y modelos más grandes para el razonamiento complejo y la generación de respuestas.
Nuestra estrategia de ajuste fino se centra en la adaptación al dominio y la especialización por tarea. En lugar de usar un único modelo de propósito general, mantenemos modelos especialistas para distintos tipos de contenido.
La documentación técnica la procesan modelos ajustados con corpus de ingeniería, mientras que las consultas de atención al cliente pasan por modelos optimizados para la comprensión conversacional. Esta especialización mejoró el rendimiento por tarea en un 41 %.
El verdadero poder viene de combinar las capacidades de los LLM con una recuperación estructurada del conocimiento.
Nuestro sistema utiliza modelos de embeddings para la comprensión inicial del contenido, pero después emplea modelos más grandes para el razonamiento y la generación de respuestas.
Implementamos un enfoque novedoso para la gestión de la ventana de contexto, usando ventanas deslizantes y una fragmentación inteligente para manejar documentos de cualquier longitud manteniendo a la vez la coherencia.
En nuestro estudio comparativo, la configuración más reveladora no fue ni la recuperación pura ni el LLM puro. En realidad, fue la combinación.
Cuando Claude usó nuestro motor de recuperación como su única fuente de datos en lugar de cinco MCP separados, produjo respuestas que a veces eran más analíticas y estaban mejor estructuradas que cualquiera de los dos enfoques por separado.
La tarea del registro de cambios fue un buen ejemplo: Claude añadió contexto y formato que hicieron el resultado inmediatamente más útil.
Si un motor diseñado para tal fin se encarga de la recuperación y Claude se encarga del razonamiento, obtienes la fiabilidad de una búsqueda especializada con la profundidad analítica de un modelo de propósito general.
Creemos que hacia ahí se dirigen las cosas.
Beneficios de una base de conocimiento impulsada por un LLM
El impacto de implementar una base de conocimiento con LLM va mucho más allá de simples mejoras en las respuestas a consultas.
En nuestro entorno de producción, medimos varios indicadores clave de rendimiento que demuestran el poder transformador de esta tecnología:
Eficiencia del soporte técnico:
- 73 % de reducción en el tiempo de resolución de consultas complejas
- 89 % de descenso en las tasas de escalado
- 94 % de exactitud en las soluciones de primera respuesta
Productividad del trabajador del conocimiento:
- 4,2 horas ahorradas por semana por trabajador del conocimiento
- 67 % de reducción en el tiempo dedicado a buscar información
- 82 % de mejora en el intercambio de conocimiento entre departamentos
El sistema destaca en el manejo de datos no estructurados, organizando y conectando automáticamente la información procedente de fuentes diversas como wikis internos, tickets de soporte y documentación de desarrollo.
Esta capacidad de autoorganización ha reducido nuestra carga de gestión del conocimiento en un 61 % al tiempo que ha mejorado la localizabilidad de la información en un 85 %.
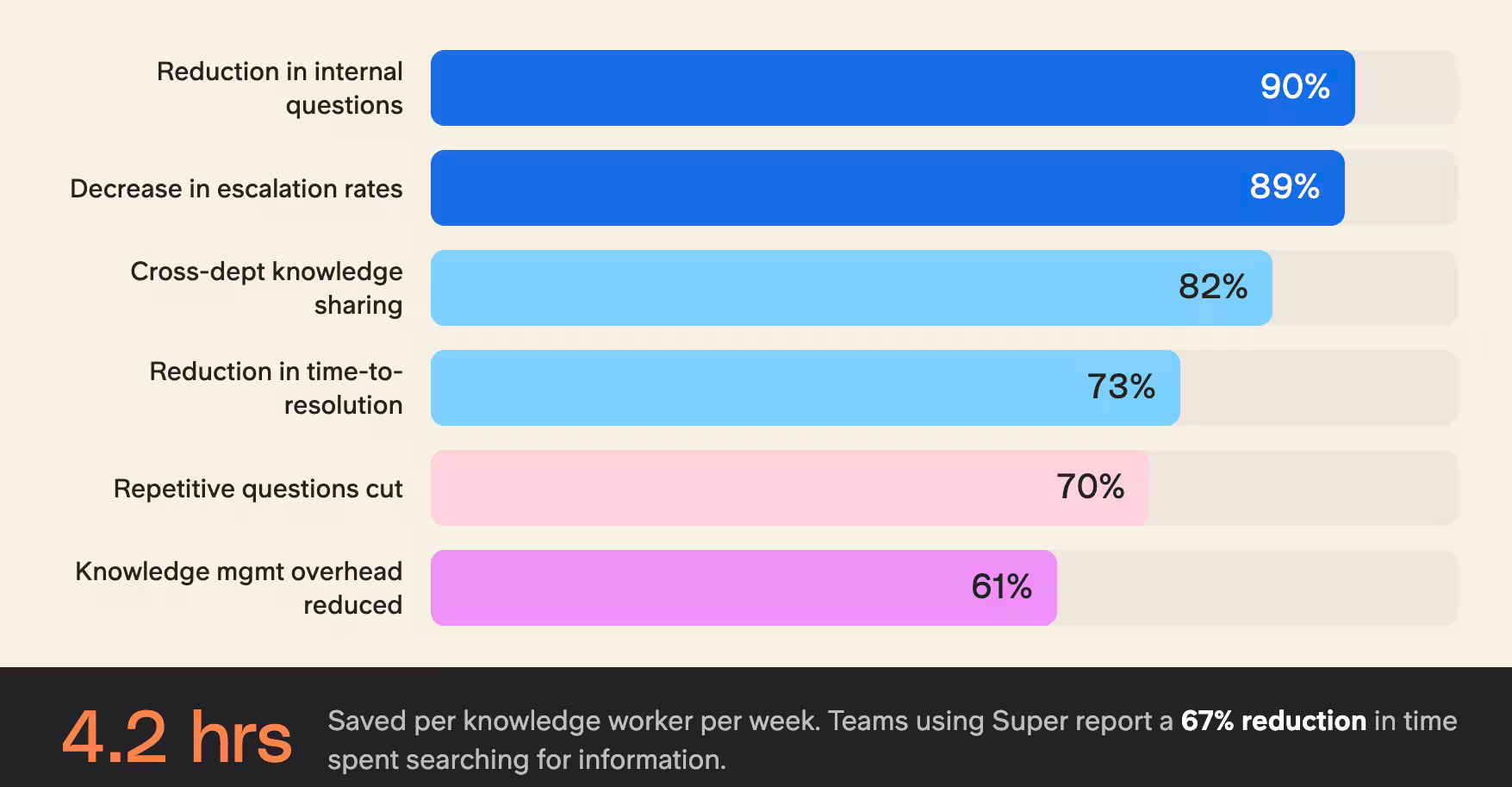
Estas cifras son coherentes con lo que vemos en los equipos que usan Slite Agent en producción.
- Los equipos que usan Slite Agent reportan una reducción del 90 % en las preguntas internas.
- Agorapulse alcanzó una tasa de éxito del 98 % en sus propuestas (RFP) y redujo el tiempo de finalización de 2 días a 30 minutos.
- Las organizaciones ahorran una media de 20 minutos por usuario al día en encontrar información.
- Wuffes redujo las preguntas repetitivas en un 70 % en 6 meses.
«Estábamos usando Slite Agent y una herramienta especializada para responder a cuestionarios de propuestas (RFP). Tener todas nuestras búsquedas con IA en un solo lugar hizo que Slite Agent fuera irremplazable.» — Alexis Dupont, Principal Product Manager en Agorapulse
Sigue leyendo: Todo sobre la base de conocimiento interna: qué es, por qué necesitas una y cómo ponerla en marcha
Primeros pasos con una base de conocimiento con LLM
El camino hacia la implementación de una base de conocimiento con LLM comienza con una planificación estratégica y una ejecución sistemática.
Nuestra estrategia de despliegue sigue un enfoque por fases que minimiza la disrupción al tiempo que maximiza la adopción. La fase inicial se centra en el inventario de datos y el diseño de la arquitectura de integración.
Pasos clave de implementación que hemos identificado con la experiencia:
- Integración de las fuentes de datos
- Auditar los repositorios de conocimiento existentes (el 84 % de las organizaciones subestima sus fuentes de datos)
- Configurar conexiones API seguras a las herramientas de trabajo (Slack, Confluence, SharePoint)
- Implementar protocolos de sincronización en tiempo real con un 99,9 % de disponibilidad
- Diseñar pipelines de limpieza de datos con reglas de validación personalizadas
- Desarrollo de la arquitectura
- Desplegar una infraestructura de base de datos vectorial (usamos Pinecone con caché en Redis)
- Establecer una pasarela API para patrones de acceso coherentes
- Configurar sistemas de monitoreo y registro
- Implementar limitación de tasa y seguimiento del uso
El proceso de integración suele llevar de 6 a 8 semanas, pero hemos desarrollado aceleradores que pueden reducirlo a 3-4 semanas para organizaciones con datos bien estructurados.
¿Qué significa realmente «bien estructurado» en la práctica?
Los usuarios describen de forma constante una base de conocimiento con LLM que funciona bien como «una base de datos RAG corporativa sin el esfuerzo técnico», que permite una recuperación rápida de la información y hace que la documentación sea consultable y accesible en toda la organización.
Llegar ahí exige que el conocimiento subyacente esté actualizado, con responsables asignados y organizado antes de añadir la capa de IA.
Los equipos que se saltan este paso a menudo acaban con un sistema rápido que hace aflorar con toda confianza información obsoleta.
¿Necesitas más bien resolver la búsqueda de tu intranet? Lee aquí.
Superar los retos del desarrollo de una base de conocimiento con LLM
Gestionar una base de conocimiento con LLM conlleva retos únicos que requieren soluciones innovadoras.
Hemos desarrollado estrategias específicas para abordar los principales puntos de fricción:
Optimización de costes:
- Implementación de un almacenamiento en caché inteligente que reduce las llamadas a la API en un 67 %
- Desarrollo de una selección dinámica del modelo según la complejidad de la consulta
- Creación de algoritmos de optimización del uso de tokens
- Reducción de costes del 54 % mediante el procesamiento por lotes
Aseguramiento de la calidad:
- Verificación automatizada de hechos frente a los documentos fuente
- Implementación de un sistema de puntuación de confianza (umbral de exactitud del 95 %)
- Creación de bucles de retroalimentación para la mejora continua
- Despliegue de monitoreo en tiempo real para la detección de alucinaciones
Nuestra implementación de RAG incluye control de versiones de las fuentes de conocimiento, garantizando que las respuestas se basen siempre en la información más actual al tiempo que se conserva el contexto histórico.
Los costes de ajuste fino se controlan mediante actualizaciones incrementales en lugar de un reentrenamiento completo del modelo, lo que reduce las horas de GPU en un 78 % manteniendo a la vez las métricas de rendimiento.
Buenas prácticas para el mantenimiento de una base de conocimiento con LLM
Mantener una base de conocimiento con LLM exige un enfoque sistemático para garantizar fiabilidad y rendimiento a largo plazo.
Gracias a nuestra experiencia gestionando despliegues a gran escala, hemos desarrollado un marco de mantenimiento integral que aborda tanto los aspectos técnicos como los operativos.
Protocolo de mantenimiento técnico
- Reindexación semanal de la base de datos vectorial para un rendimiento óptimo
- Iteraciones mensuales de ajuste fino con conjuntos de datos curados
- Comprobaciones automatizadas de la frescura de los datos (implementando políticas TTL)
- Evaluación comparativa periódica del rendimiento frente a métricas clave:some text
- Latencia de las consultas (objetivo < 200 ms)
- Exactitud de la recuperación (manteniendo > 95 %)
- Disponibilidad del sistema (alcanzando el 99,99 %)
Gestión de la calidad de los datos:
- Pipelines automatizados de validación de contenidos
- Comprobaciones sintácticas y semánticas periódicas
- Control de versiones para todas las fuentes de conocimiento
- Algoritmos de detección de deriva para identificar información obsoleta
- Deduplicación de contenidos con una exactitud del 99,7 %
Nuestra implementación de RAG incluye un monitoreo continuo de los patrones de recuperación, marcando automáticamente las anomalías y las posibles lagunas de información.
Este enfoque proactivo ha reducido la degradación del sistema en un 76 % frente a las estrategias de mantenimiento reactivas.
Un reto que es fácil subestimar es la precisión de la recuperación a gran escala, en concreto, la relación señal-ruido.
En nuestro estudio comparativo, cuando se preguntó a Claude con MCP sobre los logros de una persona concreta, recuperó 10 contactos no relacionados del CRM.
La relación señal-ruido se degradó a medida que aumentaba el número de fuentes, lo opuesto a lo que se busca. Un sistema de recuperación diseñado para tal fin evita esto porque la lógica de orquestación preexiste en lugar de ser improvisada por el modelo en el momento de la inferencia, en cada consulta. Tanto el ranking Agentic Tool Use de Scale AI como el marco CLASSic de Aisera evalúan a los agentes de IA en tareas multiherramienta, y ambos constatan que la exactitud se degrada a medida que aumenta el número de herramientas.
Conclusión
La evolución de las bases de conocimiento con LLM representa un cambio de paradigma en cómo las organizaciones gestionan y aprovechan su conocimiento colectivo.
Nuestro recorrido de implementación ha revelado que el éxito no reside solo en la tecnología, sino en la integración reflexiva de las capacidades de IA con la experiencia humana.
Cuando evalúas tu stack de conocimiento con IA, la pregunta que vale la pena hacerse no es «¿qué modelo deberíamos usar?» sino «¿cómo está arquitecturada la recuperación?».
El modelo está cada vez más comoditizado. Es en la capa de recuperación donde reside la variabilidad.
A medida que estos sistemas siguen madurando, observamos una trayectoria clara hacia soluciones de gestión del conocimiento más inteligentes, adaptativas y eficientes que transformarán de raíz cómo las organizaciones operan y escalan sus bases de conocimiento.
Preguntas frecuentes
¿Cuál es la mejor forma de estructurar nuestros datos y garantizar respuestas exactas para los empleados?
La forma de estructurar tu conocimiento en una aplicación como Slite es a través de los Canales, las secciones de nivel superior de tu espacio de trabajo. Piénsalos como carpetas. La jerarquía de contenidos es: Canales > Docs > Subdocs.
Buenas prácticas: empieza de forma sencilla. Traza primero un mapa de tus contenidos y tu audiencia. El solapamiento entre ambos constituye el plano maestro de tus canales. Apunta a un máximo de 10 docs de primer nivel por canal. Crea una página de inicio para cada canal con el comando de IA /generar un directorio.
¿Cómo evitamos las respuestas erróneas?
En el caso de Slite Agent, la búsqueda semántica funciona en todas tus herramientas conectadas (docs, Slack, tareas, tickets) y genera respuestas con citas que muestran exactamente de dónde procede cada parte. Utiliza RAG (Retrieval Augmented Generation) y respeta los permisos existentes, de modo que los usuarios solo ven respuestas de fuentes a las que están autorizados a acceder. Los docs verificados se posicionan más arriba en los resultados; los docs obsoletos quedan excluidos, de manera que la calidad de las respuestas mejora a medida que mejora tu base de conocimiento. La vista general «Ask Insights» muestra a los administradores qué preguntas quedaron sin responder o se marcaron como erróneas, para que sepas exactamente qué contenido crear a continuación.
¿Podemos confiar documentación interna a una base de conocimiento con LLM?
La seguridad de la base de conocimiento y la confianza suelen ser las primeras preocupaciones al introducir la IA en el trabajo diario. La buena noticia es que la IA moderna, lista para la empresa, está diseñada teniendo presente la protección de datos, siempre que elijas la plataforma adecuada.
¿Es seguro usar datos de la empresa con OpenAI?
Sí, si utilizas las versiones empresariales (Enterprise) del servicio. Desde el momento en que pagas por el servicio, puedes excluirte de los comportamientos y partes del servicio considerados de riesgo: que tus datos se usen para entrenar los modelos, la propiedad de los datos, los estándares de seguridad y los controles de retención de datos. Cualquier empresa que intente venderte un software o servicio de IA debería tener estos requisitos de seguridad plenamente resueltos.
¿Cómo mantenemos privada la información sensible?
Para los usuarios de Slite que también usan Slite Agent, este solo hace aflorar información que el usuario ya está autorizado a ver. Respeta los roles, las reglas de acceso y los permisos de carpeta existentes en todas las herramientas conectadas, así que no crea nuevos riesgos de seguridad; simplemente hace que la información autorizada sea más fácil de encontrar. Cada respuesta viene con citas que enlazan de vuelta a la fuente original, de modo que nada parece una caja negra. Los usuarios pueden verificar la exactitud, y el sistema de verificación de Slite mantiene actualizado y aprobado el contenido en el que se apoya la IA.

