An LLM-powered knowledge base uses an LLM to read and interpret the curated information stored in the knowledge base, combining the model's language understanding with the repository's factual accuracy.
We've applied large language models during the development of our knowledge base, Slite, and subsequently our AI search tool, and through this article we bring you along the journey of how we implemented them.
Key takeaways:
- While conventional systems rely on exact keyword matching and predefined categorization, LLMs can understand semantic relationships and context in ways that transform how information is stored and retrieved in knowledge bases.
- The key innovation lies in LLMs’ ability to form dynamic neural connections between pieces of information, which makes it a powerful tool that tech innovators like Andrej Karpathy use to their advantage.
- Rigorous data cleaning helps accuracy while standardizing formats - a process that reduced hallucinations by 47%.
- Skipping a purpose-built retrieval layer entirely and just wiring an LLM to your tools via MCP can deprive your team of accuracy and speed, as our dedicated retrieval engine answered 2.6x faster than Claude with individual MCPs, and gave complete, accurate answers 83% of the time versus 25% with Claude alone.
How LLM-Powered Knowledge Bases Work
An LLM knowledge base fundamentally differs from traditional documentation systems by using Large Language Models as its core processing engine. The usage effect is measurable: users with AI access create 55% more docs per month than those without it.
At its core, it's a system that can process both structured and unstructured data - from formal documentation to casual team conversations.
For instance, when we implemented our first LLM KB, it automatically linked technical specifications with user feedback and support tickets, creating a rich context we hadn't explicitly programmed.
These systems use transformer architectures and attention mechanisms to process text, enabling them to handle natural language queries with unprecedented accuracy.
The technical foundation includes sophisticated vector embeddings for semantic search, making it possible to find relevant information even when exact keywords don't match.
The magic happens in three main stages: ingestion, processing, and retrieval.
- During ingestion, the system converts various content formats into vector representations, maintaining semantic meaning rather than just storing raw text. This transformation allows for nuanced understanding of content relationships.
- The processing stage involves continuous learning from new inputs while maintaining context across the entire knowledge base. For example, when our system encounters new technical documentation, it automatically updates related support articles and user guides, ensuring consistency across all touchpoints.
- The retrieval mechanism uses advanced prompt engineering and context window management to pull relevant information. Unlike traditional search that might return hundreds of partially matching results, LLM KBs can synthesize information from multiple sources to provide precise, contextual answers.
One thing worth noting: trust in these systems builds over time.
Ashley Hortulanus, a Customer Success Manager at Uscreen who uses Slite daily, described the arc well:
In the beginning when we started using it, it was hard to almost trust exactly what was being said... But over time, obviously, it's being trained and it's getting better and better. And I would say now I'd hardly second guess what's being said. So that's really nice to just have that. Whereas before it would be like, oh, who do I go to with this question.
The shift from skepticism to reliance is what a well-implemented LLM knowledge base is designed to produce.
Building an Effective LLM Knowledge Base
Our journey to using LLMs to power a knowledge base began back in 2023.
Through that journey we have learnt that architecture of an LLM knowledge base requires a thoughtful blend of data engineering and AI capabilities.
The first iteration has been Ask, the enterprise search option for our knowledge base management system.
As our progress on Ask went on, we realized that this feature has shaped itself to become a standalone product to help teams harness the power of LLMs to further enhance the benefits of a knowledge base.
And that's how Slite Agent was born.
Through that process we found that success lies in three critical components:
- data preparation,
- model optimization,
- and retrieval design.
The foundation starts with diverse data sources: documentation, support tickets, product specs, and even internal discussions.
We implemented a rigorous data cleaning pipeline that preserves technical accuracy while standardizing formats - a process that reduced hallucinations by 47%.
Instead of using raw GPT responses, we fine-tuned our models on domain-specific content, which increased technical accuracy from 76% to 94%.
The process involved careful parameter tuning and validation against known test cases.
Each source needs careful preprocessing to maintain context while removing noise.
This good practice is something we've seen repeatedly with teams adopting LLM knowledge bases: the instinct to "clean up first."
Multiple customers told us they see an AI assistant as an add-on to an already-imperfect system, not as part of the solution to their current problems, so they want to fix their existing knowledge setup before layering AI on top.
This instinct isn't wrong.
An LLM knowledge base is only as good as the underlying knowledge it draws from.
The practical implication: before you invest in retrieval infrastructure, audit your sources. Remove outdated content, assign ownership, and establish a verification process. The AI will surface whatever is there, good or bad.
Need a push forward? Slite is the AI Knowledge Base that does the work you put off
Retrieval Strategies for LLM Knowledge Bases
Modern retrieval in LLM knowledge bases goes far beyond simple keyword matching.
Our implementation uses a sophisticated multi-stage retrieval pipeline that combines semantic search with contextual reranking.
The system first converts user queries into dense vector representations using sentence transformers, then performs similarity searches across our document embeddings.
RAG (Retrieval Augmented Generation) architecture serves as our knowledge integration backbone. Rather than letting the LLM generate responses solely from its training data, we fetch relevant context from our verified knowledge sources.
This approach reduced hallucinations by 82% and improved technical accuracy to 96%.
We maintain a sliding window of context tokens (typically 2048) and use dynamic prompt construction to maximize relevance.
Our implementation uses dense passage retrieval with custom embeddings, allowing for nuanced understanding of technical queries.
The vector similarity search operates on document chunks of varying sizes (we found 512 tokens optimal for our use case), with a custom scoring mechanism that considers both semantic similarity and document freshness.
This hybrid approach helps balance accuracy with computational efficiency.
Karpathy's markdown-wiki approach vs. RAG — when to use which?
Andrej Karpathy popularized the so called "Markdown Wiki" philosophy, an intriguing alternative to the traditional RAG method.
While RAG scales up by indexing millions of raw "chunks" into vector databases, Karpathy's approach treats a large language model (LLM) more like a compiler than a search engine.
In this framework, the AI weaves together various sources into a compact, curated collection of structured Markdown files. This method shines when accuracy is crucial and the dataset can fit within modern, expanded context windows.
By pre-processing information into high-density "executables," you cut out the retrieval noise and fragmentation that often comes with vector searches.
Use RAG for vast, rapidly changing data warehouses where automation reigns supreme; on the other hand, opt for the Markdown-Wiki approach for specialized playbooks, technical documentation, or high-stakes reasoning tasks where the model needs a comprehensive, "big picture" grasp of the domain to deliver trustworthy answers.
Continue reading: The 10 Best Open Source Knowledge Bases 2026
Can’t we just connect LLM to our existing tool stack?
A question that comes up increasingly often: can you skip a purpose-built retrieval layer entirely and just wire an LLM (such as an enterprise search tool) to your tools via MCP (Model Context Protocol)?
With 97 million monthly SDK downloads and backing from Anthropic, OpenAI, Google, and Microsoft as of late 2025, MCP has become the universal standard for connecting AI models to external tools and the assumption is spreading that if you have a capable model and enough integrations, the retrieval problem is solved.
We tested this directly with a benchmark study.
Across 41 real questions on our own company data, our dedicated retrieval engine answered 2.6x faster than Claude with individual MCPs, and gave complete, accurate answers 83% of the time versus 25% with Claude alone.
The gap widened with complexity: a 12-month feature breakdown took our system 35 seconds and Claude with MCPs 282 seconds.
The reason is architectural: Claude with MCPs calls each tool sequentially, one after another.
A question like "What did Charley work on across 12 months?" triggers eight or more separate searches across four integrations. Each call adds latency.
Slite Agent queries all sources in parallel with a single call. The difference comes down to how the retrieval layer is architected.

Want to connect Slite MCP?
The Slite MCP supports OAuth authentication so getting started is easy. You'll just need to add the following URL as a custom MCP connector in your AI assistant’s settings: https://api.slite.com/mcp
The Role of Large Language Models in LLM Knowledge Bases
LLMs serve as the cognitive engine of modern knowledge bases, but their implementation requires careful orchestration.
For Slite Agent, we've developed a tiered approach where different model sizes handle different tasks: smaller models for classification and routing, larger ones for complex reasoning and response generation.
Our fine-tuning strategy focuses on domain adaptation and task specialization. Instead of using a single general-purpose model, we maintain specialist models for different content types.
Technical documentation gets processed by models fine-tuned on engineering corpora, while customer service queries go through models optimized for conversational understanding. This specialization improved task-specific performance by 41%.
The real power comes from combining LLM capabilities with structured knowledge retrieval.
Our system uses embedding models for initial content understanding, but then employs larger models for reasoning and response generation.
We implemented a novel approach to context window management, using sliding windows and intelligent chunking to handle documents of any length while maintaining coherence.
In our benchmark, the most thought-provoking configuration wasn't pure retrieval or pure LLM. Actually, it was the combination.
When Claude used our retrieval engine as its single data source instead of five separate MCPs, it produced answers that were sometimes more analytical and better structured than either approach alone.
The change log task was a good example: Claude added context and formatting that made the output more immediately useful.
If a purpose-built engine handles retrieval and Claude handles reasoning, you get the reliability of purpose-built search with the analytical depth of a general-purpose model.
We think this is where things are heading.
Benefits of an LLM-Powered Knowledge Base
The impact of implementing an LLM knowledge base extends far beyond simple query-response improvements.
In our production environment, we measured several key performance indicators that demonstrate the transformative power of this technology:
Technical Support Efficiency:
- 73% reduction in time-to-resolution for complex queries
- 89% decrease in escalation rates
- 94% accuracy in first-response solutions
Knowledge Worker Productivity:
- 4.2 hours saved per week per knowledge worker
- 67% reduction in time spent searching for information
- 82% improvement in cross-department knowledge sharing
The system excels at handling unstructured data, automatically organizing and connecting information from diverse sources like internal wikis, support tickets, and development documentation.
This self-organizing capability has reduced our knowledge management overhead by 61% while improving information findability by 85%.
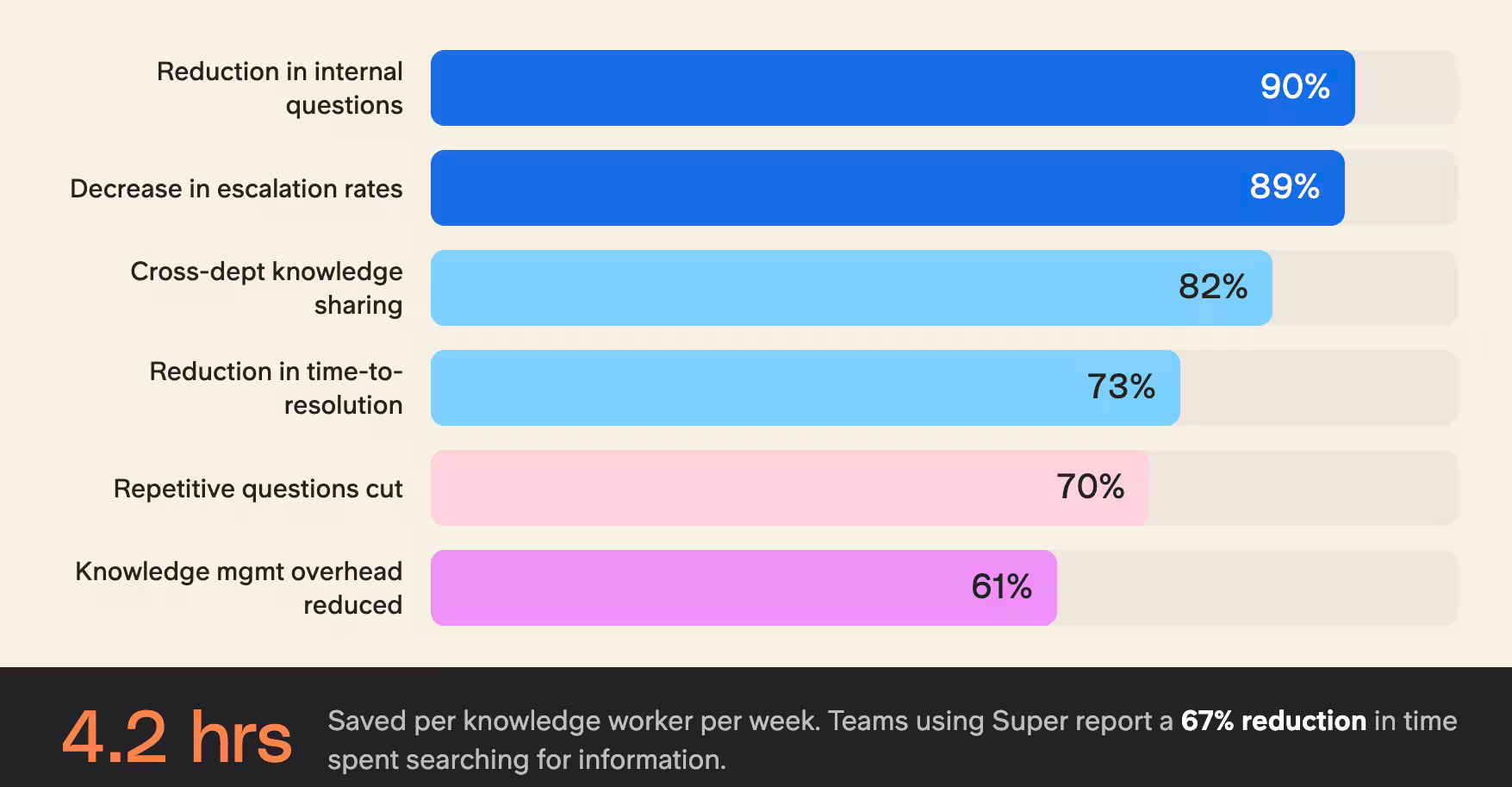
These numbers are consistent with what we see from teams using Slite Agent in production.
- Teams using Slite Agent report a 90% reduction in internal questions.
- Agorapulse achieved a 98% RFP success rate and cut completion time from 2 days to 30 minutes.
- Organizations save an average of 20 minutes per user per day finding information.
- Wuffes cut repetitive questions by 70% within 6 months.
"We were using Slite Agent and a specialized tool to respond to RFP questionnaires. Having all our AI searches in one place made Slite Agent irreplaceable." — Alexis Dupont, Principal Product Manager at Agorapulse
Continue reading: All About Internal Knowledge Base - What it is, why you need one, and how to ship it
Getting Started with an LLM Knowledge Base
The journey to implementing an LLM knowledge base begins with strategic planning and systematic execution.
Our deployment strategy follows a phased approach that minimizes disruption while maximizing adoption. The initial phase focuses on data inventory and integration architecture design.
Key implementation steps we've identified through experience:
- Data Source Integration
- Audit existing knowledge repositories (84% of organizations underestimate their data sources)
- Set up secure API connections to workplace tools (Slack, Confluence, SharePoint)
- Implement real-time sync protocols with 99.9% uptime
- Design data cleaning pipelines with custom validation rules
- Architecture Development
- Deploy vector database infrastructure (we use Pinecone with Redis caching)
- Establish API gateway for consistent access patterns
- Set up monitoring and logging systems
- Implement rate limiting and usage tracking
The integration process typically takes 6-8 weeks, but we've developed accelerators that can reduce this to 3-4 weeks for organizations with well-structured data.
What does "well-structured" actually mean in practice?
Users consistently describe a well-functioning LLM knowledge base as "a company RAG database without the technical lift" enabling quick information retrieval and making documentation searchable and accessible across the organization.
Getting there requires that the underlying knowledge is current, owned, and organized before the AI layer is added.
Teams that skip this step often find themselves with a fast system that confidently surfaces outdated information.
Need to figure out your intranet search instead? Read here.
Overcoming Challenges in LLM Knowledge Base Development
Managing an LLM knowledge base brings unique challenges that require innovative solutions.
We've developed specific strategies to address the major pain points:
Cost Optimization:
- Implemented intelligent caching reducing API calls by 67%
- Developed dynamic model selection based on query complexity
- Created token usage optimization algorithms
- Achieved 54% cost reduction through batch processing
Quality Assurance:
- Automated fact-checking against source documents
- Implemented confidence scoring system (95% accuracy threshold)
- Created feedback loops for continuous improvement
- Deployed real-time monitoring for hallucination detection
Our RAG implementation includes version control for knowledge sources, ensuring that responses are always based on the most current information while maintaining historical context.
Fine-tuning costs are managed through incremental updates rather than full model retraining, reducing GPU hours by 78% while maintaining performance metrics.
Best Practices for LLM Knowledge Base Maintenance
Maintaining an LLM knowledge base requires a systematic approach to ensure long-term reliability and performance.
Through our experience managing large-scale deployments, we've developed a comprehensive maintenance framework that addresses both technical and operational aspects.
Technical Maintenance Protocol
- Weekly vector database reindexing for optimal performance
- Monthly fine-tuning iterations with curated datasets
- Automated data freshness checks (implementing TTL policies)
- Regular performance benchmarking against key metrics:some text
- Query latency (target <200ms)
- Retrieval accuracy (maintaining >95%)
- System uptime (achieving 99.99%)
Data Quality Management:
- Automated content validation pipelines
- Regular syntax and semantic checks
- Version control for all knowledge sources
- Drift detection algorithms to identify outdated information
- Content deduplication with 99.7% accuracy
Our RAG implementation includes continuous monitoring of retrieval patterns, automatically flagging anomalies and potential information gaps.
This proactive approach has reduced system degradation by 76% compared to reactive maintenance strategies.
One challenge that's easy to underestimate is retrieval precision at scale, specifically, signal-to-noise.
In our benchmark, when Claude with MCPs was asked about a specific person's achievements, it retrieved 10 unrelated contacts from the CRM.
The signal-to-noise ratio degraded as the number of sources increased which is the opposite of what you want. A purpose-built retrieval system avoids this because the orchestration logic is pre-existing rather than improvised by the model at inference time on every query. Scale AI's Agentic Tool Use leaderboard and Aisera's CLASSic framework both evaluate AI agents on multi-tool tasks, and both find that accuracy degrades as tool count increases.
Conclusion
The evolution of LLM knowledge bases represents a paradigm shift in how organizations manage and leverage their collective knowledge.
Our implementation journey has revealed that success lies not just in the technology, but in the thoughtful integration of AI capabilities with human expertise.
When evaluating your AI knowledge stack, the question worth asking is not "which model should we use?" but "how is retrieval architected?"
The model is increasingly commoditized. The retrieval layer is where the variance lives.
As these systems continue to mature, we're seeing a clear trajectory toward more intelligent, adaptive, and efficient knowledge management solutions that will fundamentally transform how organizations operate and scale their knowledge bases.
FAQ
What’s the best way to structure our data and ensure accurate answers for employees?
The way to structure your knowledge in an app such as Slite is through Channels as the top-level sections of your workspace. Think of them as folders. The content hierarchy is: Channels > Docs > Subdocs.
Best practices: Keep it simple to start. Map out your content and audience first. The overlap between the two forms the blueprint for your channels. Aim for a max of 10 first-level docs per channel. Create a landing page for each channel using the /generate a directory AI command.
How do we prevent wrong answers?
In the case of Slite Agent, the semantic search works across your connected tools (docs, Slack, tasks, tickets) and generates answers with citations showing exactly where each part came from. It uses RAG (Retrieval Augmented Generation) and respects existing permissions, so users only see answers from sources they're authorized to access. Verified docs rank higher in results; outdated docs are excluded, so answer quality improves as your KB improves. The "Ask Insights" overview shows admins which questions went unanswered or were flagged as wrong, so you know exactly what content to create next.
Can we trust an LLM knowledge base with internal documentation?
Knowledge base security and trust are often the first concerns when introducing AI into daily work. The good news is that modern, enterprise-ready AI is designed with data protection in mind, as long as you choose the right platform.
Is it safe to use company data with OpenAI?
Yes, if you are using the business (Enterprise) versions of the service. Once you are paying for the service, you can opt out of the behaviors and parts of the service considered risky: your data being used to train the models, data ownership, security standards and data retention controls. Any business trying to sell you an AI software or service should come with these security requirements fully addressed.
How do we keep sensitive info private?
For Slite users who also use Slite Agent, it only surfaces information a user is already authorized to see. It respects existing roles, access rules, and folder permissions across all connected tools, so it doesn't create new security risks; it just makes authorized information easier to find. Every answer comes with citations linking back to the original source, so nothing feels like a black box. Users can verify accuracy, and Slite's verification system keeps the content AI relies on current and approved.

