How to use language models' tacit knowledge
When working with language models (LMs), there is a tension between "What you want the LM to do" and "What the LM is competent at". When building Slite's knowledge-management AI assistant, our first prompts used long lists of rules and schemas to try to tell the LM what we wanted. But this approach failed, because "how to manage a knowledge-base" is tacit knowledge: it can't be succinctly described; it's only learned through experience. We moved towards a two-step prompting technique which instead exploits the LM's tacit knowledge. In this post, I describe this technique with two case studies: name-dropping, and using custom HTML.
Tacit vs. explicit knowledge
In the field of knowledge management, there's a distinction between tacit and explicit knowledge. Knowledge-bases like Slite record explicit knowledge, like "We use Stripe for payments." But people also have tacit knowledge, like why our payments system looks like this, or how to design a successful payment flow. Tacit knowledge is difficult to express or acquire, except through lots of examples and experience.
Language models are the same! They have lots of explicit knowledge, like "Paris is the capital of France." But they also have lots of tacit knowledge, like how to write an idiomatic bash script, or how to identify the important aspects of a document.
While building Slite's AI Assistant, we discovered that our application and engineers have a lot of tacit knowledge that the LM did not have:
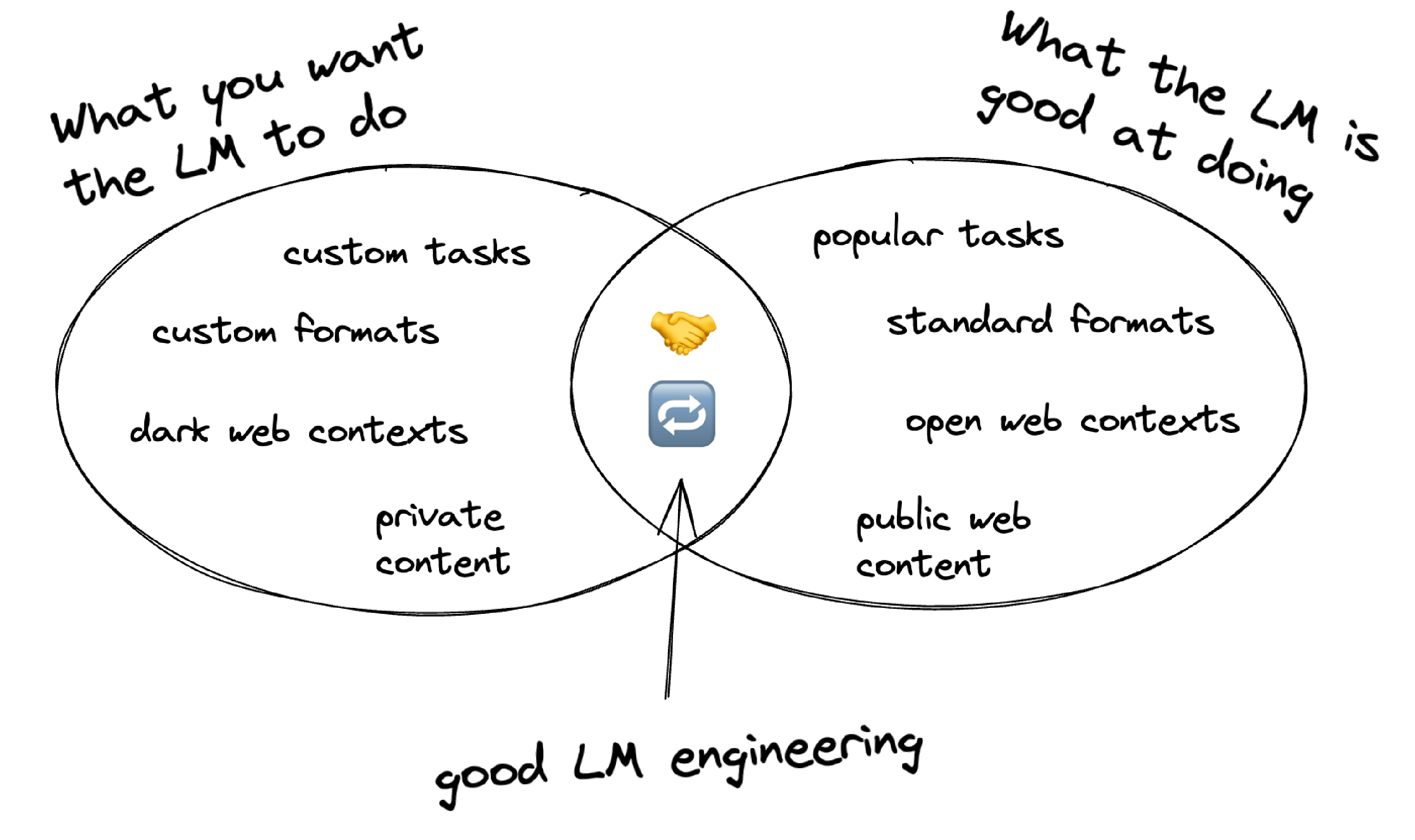
This is a big problem, because you can't put tacit knowledge in a prompt! You can try, but you will fail. Here are two examples of our own attempts, failures, and how we got past them.
1: Name-dropping authorities
Slite has a feature called Improve Formatting. Most people skim-read. “Improve formatting” helps them by converting walls-of-text into lists, headings, and highlights.
Our initial approach was to tell the LM all the rules for how to "improve formatting":
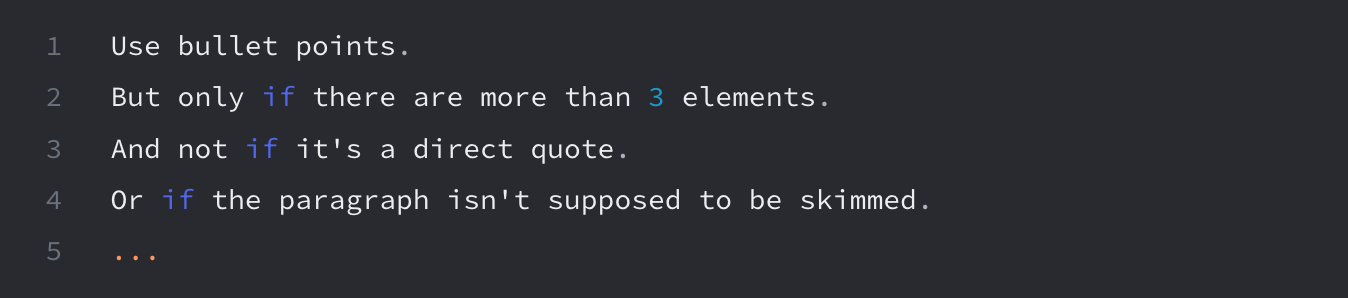
And the rules kept piling up. Exceptions upon exceptions. The thing is, there are no hard rules for how to "improve formatting". There is a large amount of tacit knowledge.
Your job as a prompt engineer is not to transfer your tacit knowledge to the LM, but to exploit the tacit knowledge embedded in the LM. This is a two-step process:
- Find the LM's tacit knowledge that most closely resembles your own.
- Bridge those two worlds.
For step 1, the best way we found was to name-drop authorities. An important authority in this field is Neilsen Norman Group. Over 25 years, they've produced a large amount of work on web usability, and a lot of this is about optimizing web content for scanning and skimming.
So we transformed our explicit list of rules into a much shorter prompt:

For step 2, we compared and contrasted the LM's tacit knowledge with our own, then added exceptions to the prompt. For example, we added:

2: HTML as a universal format
Slite docs are JSON following a custom schema, like:

We use this format everywhere internally. Naturally, our first prompting attempts used this format. We would send a JSON fragment to the LM, and ask it to modify it in some way (such as "Simplify language"), and expect the LM to output a modified JSON fragment.
We quickly ran into problems. The LM would hallucinate element types, mis-use elements, and generally didn't understand our document format.
Our response was to describe the schema in the prompt, and how to use each element. E.g.

This improved matters slightly, but made the prompt huge. And it turns out, even if we could get the LM to understand the JSON schema, this wasn't even the big problem.
The LM never really grokked our doc format. There is a lot of "tacit knowledge" about idiomatic doc structure, when to use a hint block, etc. Our engineers have absorbed all that, but the LM has not.
We considered switching to Markdown. Markdown is the most popular format for interchange with LMs. But it's not ideal for Slite, because we have many element types that do not fit. Think user mentions, like @Jim Fisher.
We settled on HTML as a universal format. The LM has seen huge amounts of HTML. It knows, for example, when to use an <aside> block — tacit knowledge that's hard to put into words in a prompt.
Conclusion
When building our AI-powered knowledge base, we faced challenges in using language models because of differences in tacit knowledge between our product and the LM. Initially, we tried to teach the LM our rules and formatting directly, but it was not effective, because this tacit knowledge is hard to convey and can only be gained through experience. Instead, we found success with two methods: 1) Referring to authorities like the Neilsen Norman Group to leverage the LM's internalized best practices for content formatting, and 2) Using HTML as a universal format for content exchange, taking advantage of the LM's extensive familiarity with HTML. These methods successfully bridged the gap between our tacit knowledge and that of the language model.

