How we built Super - The 1st reliable Enterprise Search

If you work with information, you are, like me, a knowledge worker.
Fundamentally, our added value is our creativity, but most of our time is spent moving information around. Our creative work is what creates asymmetric outcomes, and yet we spend hours on busy work: tasks that are essentially copy-paste with a bit of extra reasoning.
The first wave of tools trying to help us with automation, Zapier, n8n, Make, only scratched the surface. We're in the middle of the second wave, the big wave. AI automation.
Most people misunderstand it. It's not about automating with more intelligence but like a stranger would. The revolution is having truly intelligent assistance from someone understanding our personal context as deeply as we do.
Think about a support agent handling their 100th ticket this week, doing a dance between the customer and nudging their teammates for answers, again and again. Or think of a sales representative, filling out their 3rd prospect list of questions of the month.
They're spending hours jumping between resources, copying and pasting information. No creativity involved - just time consumed.
The era of AI automation will start by unlocking access to our personal contexts, to our team information. Then only our tools will eliminate our meaningless copy-paste work and let us focus on creation.
It meant creating Super.
Super will be the assistant that truly understands your work context. It knows what your team knows, answers like a colleague would, and most importantly - it gets what you're trying to achieve. While others focus on building better search engines, we've taken a different path.
Yes, Super includes the most advanced enterprise AI search available - but that's just half of your work. Search still puts you in the middle, forcing you to piece together information from multiple sources.
Super goes beyond search. It actively assists you, handling the context-heavy tasks that don't require creative input. It reduces your work to its pure essence: the human elements that truly matter - your creativity, your emotional intelligence, your ability to innovate.
This essay is everything about Super.
Not just the technical architecture (though we'll get deep into our RAG implementation and security model), but the full story: why we built it, how it works, what we learned, and where we're headed. From the early prototypes to production challenges, from UX decisions to enterprise scaling—this is the comprehensive Super breakdown.
In this deep-dive, we'll cover:
- The evolution of enterprise search and why existing solutions fall short
- How Super processes and secures your company's knowledge
- The technical architecture powering our semantic understanding
- Real-world usage patterns and what they taught us
- Our product roadmap and vision for the future
No glossing over the hard parts. No hiding the challenges. This is the full Super story.
Why we built Super
Short answer: We built Super to address the innately chaotic nature of knowledge.
Long answer:
For almost a decade, I've been obsessed with a mission: giving clarity at work by letting teams tap in their shared context, anywhere and anytime.
This led me to build Slite, a knowledge base that struck the perfect balance between simplicity and power. But even as teams embraced it, we kept running into the same hard truth: knowledge can never be fully centralized. It lives everywhere - in Slack threads, in email chains, in the daily back-and-forth of work.
You can't possibly repurpose all of it in well written docs.
We always knew AI would be the solution, eventually. I remember mentioning in our YC applications how vectorisation libraries like word2vec or doc2vec were signs of machines grasping meaning, and how it would logically transform our industry.
And ChatGPT happened. While our team was enjoying Christmas break, Florian - my AI partner in crime - and I were building Ask. It would become the world's first AI search system for private knowledge bases. We proved it could work, but this early success showed us something crucial: we needed more.
More data, more intelligence, and most importantly, we needed to think beyond just search.
In March 2024, coming back from my twin's parental leave, everything crystallized. It was time to go beyond AI search and make something 10x more useful for knowledge workers.
Why a new tool?
Traditional search expects a tidy world. It wants every piece of knowledge filed away in labeled documents, all in one place. LLMs work great with public, trusted information. But real work isn't like that. Knowledge lives everywhere, it flows through meetings, pops up in Slack DMs, hides in document comments, and spreads through hallway chats.
Work needed a better way to handle knowledge. No current tool (or their combination) would sufficiently fix the problem. Hence we had to start from the start.
Super is the only tool designed with the following axioms in mind:
- Information will always spread across tools.
- AI tools are not exclusive to power users. They need to be dead simple, precise, and feel familiar.
- Search makes for 50% of our workflows, AI will assist in finding and manipulating knowledge.
- When AI relies on search, humans need deep control and visibility on sources.
- Raising the quality of team AI assistants requires a way to verify knowledge and to fill the gaps of information.
How we built Super
We didn't start out planning to create a product called "Super." The name emerged organically during our development process. After building Slite and then our AI search feature called "Ask" we realized we needed something that transcended conventional categories. During a team brainstorming session about our vision for this new tool, someone remarked that what we were describing wasn't just an assistant or a search tool—it was something that sat above all existing work applications, connecting them and making them more useful. And thus, started a project called “AskX” - Super’s codename.
So technically, Super has been in the works for 24 months. It really started in 2023.
2023: Starting with RAG
We built Ask - our AI search for Slite' knowledge bases. It was the first RAG for private knowledge tool ever released and teams loved it.
But as we watched people use it, we kept seeing the same pattern: they'd find only part of their answers, and needed to jump to other tools to get the full picture.
Early 2024: Opening Up Data Sources
It felt like we were onto something big. But we missed part of the picture, and other tools on the market were hitting the same limit.
What’s the use of reading the project plan in your documentation when it already changed in 4 different ways on your project management tool when the real work starts?
So we started pulling in data from everywhere.
May 2024: Bye-bye, chat interface.
This was a turning point. We'd been stuck thinking of Super as a chatGPT for enterprise, interface included.
But the UX of chat is incredibly un-opinionated. Answers at work require 2 things chat will struggle with:
- A focus on sources. When AI constantly relies on search, sources need to be first class citizens.
- Specific experiences for specific use cases. Claude Artefacts and OpenAI canvas hint in this direction, for AI applications we'll need to go even further.
Chat interfaces are perfect for messaging your friends, but that’s about all they’re perfect for. And knowledge work is too complicated to be fixed by the same interface you use for your SMS.
So we re-thought our interface with 1st principle thinking, to focus on sources and to make it handle various enterprise usages.
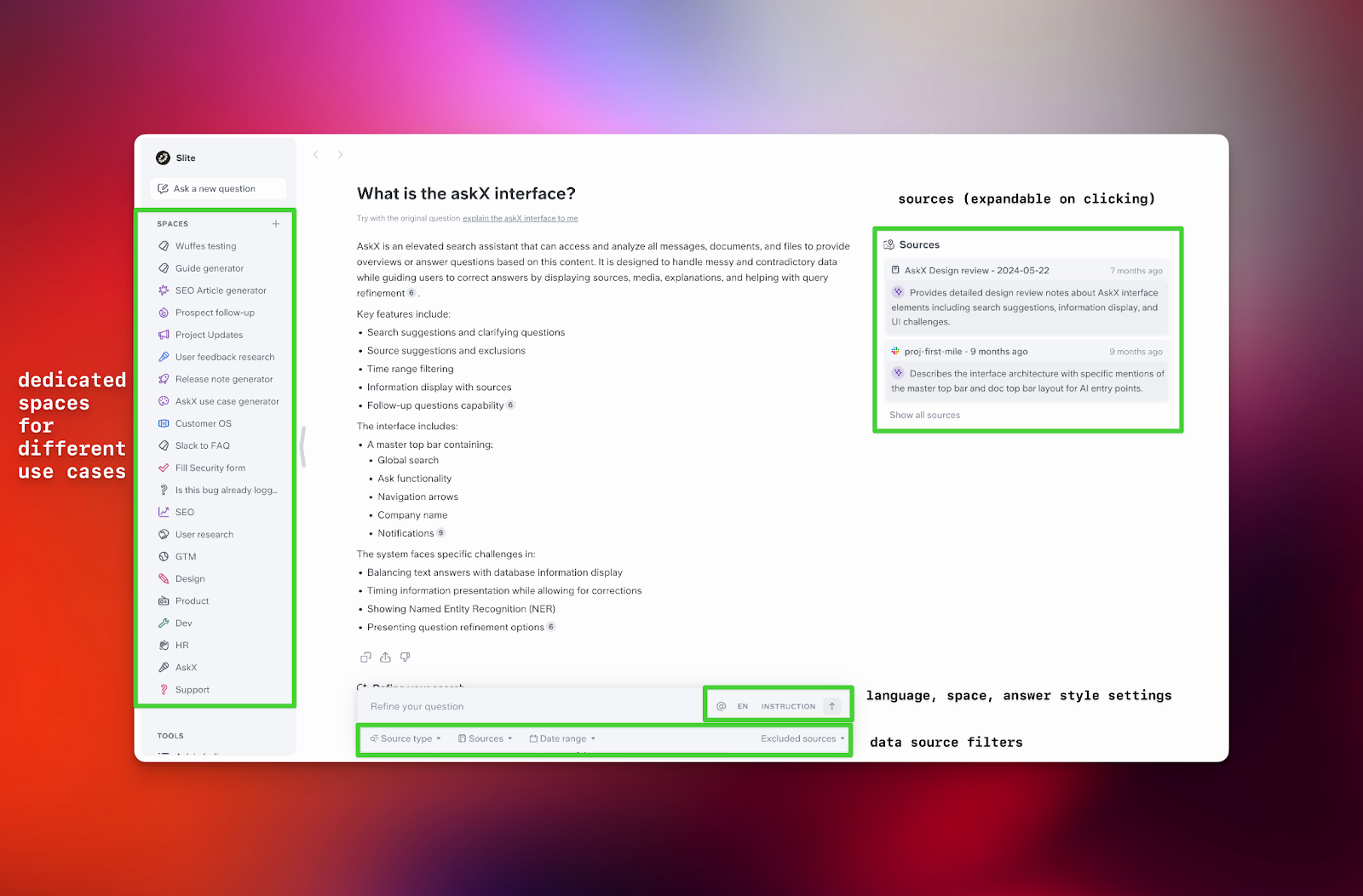
And a whole panel on the right is here to put even more light on this context, explaining in plain sentences which source was used and why, making it easy to review.
At the bottom, a powerful filtering bar lets you specify instructions and narrow down exactly what you're looking for by sources, date range and more,
Finally, "spaces" are here to tailor Super to your use cases - from writing release notes to handling customer questions. Each space is tuned for its specific job.
July 2024: Building for contradictions
We could lie (like many tools) and say Super always works.
It doesn't. Even with the best technology, if a tool relies on human data, it will get incorrect information, or contradictions.
We designed Super to make the whole experience work despite these.
- When we detect un-clarities, we ask you for precisions
- If you don't set filters, our AI search automatically detects the appropriate possible filters and runs a few searches in parallel to maximise the chance of getting the full picture before answering.
- And of course you can keep refining, following on your original question, excluding sources, changing filters.
It turned out users don't need perfect answers - they need above everything else clarity on the process.
November 2024: Beyond search
We reached a point where the chance of finding the right answer with Super was close to 100%. Our next chapter was to go beyond search, and have AI remove much more of your workload.
To do so, we design tools and experience specific to the most recurring tasks we saw: report generation, turning data into charts, summary from multiple tools, RFP and security forms filling, etc.
That will be our continuous lane of work in 2025, along with adding more sources.
Who is Super for?
Super is for anyone who works with information - which is pretty much everyone. Think about it: whether you're making decisions, analyzing data, or creating documents, your job comes down to finding and using information effectively.
Here's how different teams are using it:
Support & Sales Teams
- Finding accurate answers for customers in seconds instead of digging through support docs
- Pulling up product details and pricing info during live calls
- Building comprehensive response templates from past conversations
Operations Teams
- Accessing step-by-step procedures instantly
- Keeping track of process changes across departments
- Finding the right person to contact for specific issues
Product & PMM Teams
- Synthesizing user feedback from multiple channels
- Drafting release notes by pulling from engineering updates
- Creating feature announcements that align with past messaging
- Building product specs based on historical decisions and context
Leadership Teams
- Creating quick digests of team progress
- Preparing board updates with accurate metrics
- Staying on top of cross-team initiatives
Marketing Teams
- Gathering consistent product messaging across channels
- Building campaign materials based on past performance
- Creating content that aligns with company voice and strategy
New Team Members
- Getting up to speed without endless document searches
- Learning team context and history quickly
- Finding relevant examples of past work
The common thread? Everyone needs to find, understand, and use information. Super just makes this core part of work faster and more reliable.
How to use Super
To get access to Super, click here.
Let's start with the basics: using Super can be as natural as asking a colleague a question. No special syntax needed, no complex search operators to memorize. Just type what you're looking for, the way you'd actually ask it.
Getting better results is all about how you frame your questions:
- Think conversations, not keywords. "What's our refund policy for enterprise customers?" works better than just "refund policy"
- Need something specific? Put quotes around key terms: "enterprise pricing" or "deployment process"
- Add time context when it matters: "Q2 revenue targets" or "latest security protocols"
- Quick filtering with @: @slack, @marketing strategy or @RFP space
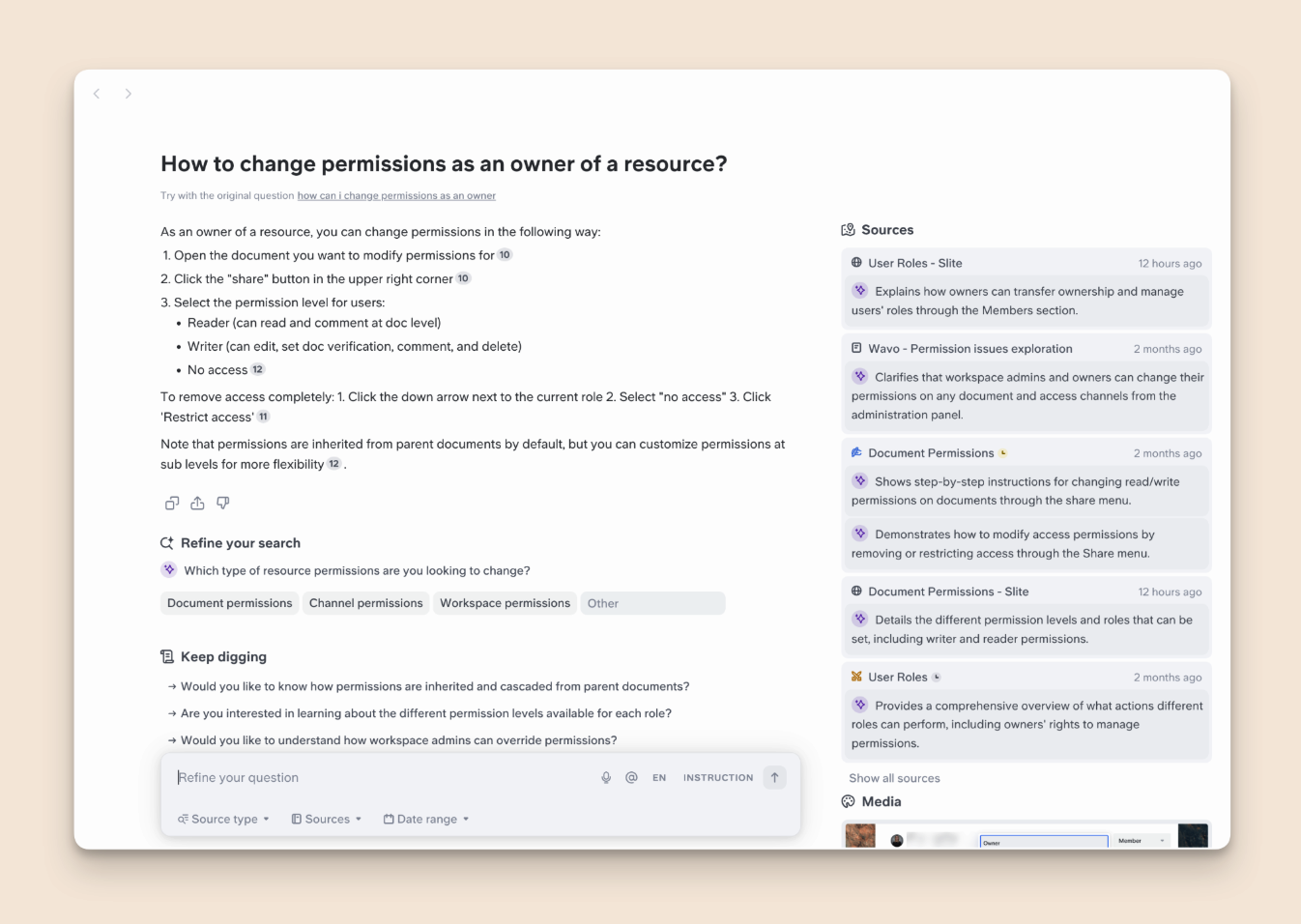
After your first reply, it's all about refining and digging. Super might ask for clarification or suggest related queries you hadn't thought of. Need to refine your search? Just add more context conversationally—Super will understand and adjust.
You can access Super in many ways, whatever fits your workflow best:
- Through the web app, compatible on mobile
- With our Slack extension, by mentioning @super in a channel or thread
- With our web browser extension (cmd/ctrl + shift + K) - perfect for asking without leaving your window or getting fast access to Super in new tabs.
- You can also build your own interfaces with our API endpoint.
- Finally if you also use Slite as your Knowledge base, it will be accessible directly there.
The tech under the hood of Super
At its core, Super is built on two powerful technologies: RAG (Retrieval Augmented Generation) and LLM (Large Language Models). But unlike simpler enterprise search tools that rely on basic keyword matching, we've implemented a model-based approach that understands context, entities, and relationships.
Search & Accuracy
We use a hybrid search system that's more sophisticated than it might appear. When you search, multiple query methods run simultaneously, each optimized for different types of information.
The results then go through a reranking system—think of it as a second, more discerning pass that uses a computationally intensive model to ensure accuracy.
One of our biggest challenges was handling contradictions in company data. After all, your company knowledge isn't a neat, organized library—it's a living, breathing ecosystem where information evolves and sometimes conflicts. We solved this by implementing smart filtering controls that help users navigate through different versions and sources of truth.
The UX
The UX, by far, was the most interesting part for us. Like we explained that the chat interface was too shallow, it did one thing well, it was familiar and it was easy. So we built for context, refinements, and navigation around it - while your Q&A still remains front and center.
Spaces were a very early part of the UX already. The next important bit was sources - we put sources in plain sight so that your team can easily spot information clashes, and refine their filters to have the most accurate result. And then came formatting and filtering switches - all nested right where you type into Super. This way, we were able to keep all user input/tweaking functions in the bottom centre of the screen so it's always accessible but never intrusive.
Our answer layout is also built to adapt dynamically to the type of answer generated.
Real-time Intelligence
As you type, Super's NER system is identifying and categorizing entities in your query—people, projects, dates, products. This helps us understand not just what you're asking, but the context around your question.
Building Super meant solving some interesting technical puzzles. How do we show database results alongside unstructured text? When should we display information versus waiting for more context? How do we visualize entity relationships without overwhelming the user?
Our solution was to build an interface that's powerful enough for power users but intuitive enough for everyone else. It's why you'll find advanced features like source suggestions and time range options naturally integrated into the question refinement experience.
Orchestration
If you’re reading an essay about a tool as proprietary as Super, you must’ve used the canvas features in chatGPT and Claude by now. Having your output built side-by-side is great. And especially now, because AI isn’t perfect.
Getting AI to do anything
How does Super handle your data?
Your enterprise data requires the highest security standards. Here's exactly how Super works:
Security Foundation
- SOC 2 Type II certified infrastructure
- EU-based servers with full GDPR compliance
- End-to-end encryption for all data processing
- Complete audit trails of every system interaction
- Your data is never used to train models
Permissions
Super is designed to mirror to the best extent possible the security controls of other tools in real-time.
If someone can't access an information directly, they shouldn't see it in Super, and change of permissions are reflected in Super results.
Our preferred way of doing so is to leverage email permissions when exposed by other platforms (Slack, GDrive, Confluence, etc.), and use them to see what the user can access or not based on their verified email in Super.
If the platform doesn't expose permissions, we explain it clearly to the admin adding a new source. See our documentation for the exhaustive list of our sources and how they are built.
Compliance & Monitoring
Super, as part of Slite services, is GDPR and SOC 2 type II compliant.
Our security team runs continuous monitoring and regular penetration testing. Technical teams can access detailed documentation of our security architecture and data flows.
These aren't just features we've added—they're core to how Super functions. We're happy to discuss specific security requirements for your organization.
Pricing and packaging
Get started with Super at $20 per user/month for the monthly billing and $15 per user/month if you choose to go with annual billing. And of course, if you’re an existing Slite customer, we have some sweet discounts for you.
Running a larger team or need custom solutions? We offer degressive enterprise pricing that fits your scale, with options for custom integrations and dedicated support. Let's talk about what your team needs!
The Road Ahead
We've cracked something fundamental in 2024. Through a precise blend of technical and design innovation, we've built what we believe is the most reliable AI-powered team assistant available today. You can pull in any source and get elaborate answers in seconds.
Finding information is just the start. We're now building tools that help you get work done. Our first launches like automatic weekly digests and RFP fillers have given us the confidence to push on assistants. So we’ll be doing 2 things this year:
- Build automations - Assistants and automations are gonna start popping up in Super through the year for all sorts of use cases.
- Build more data sources - More use cases, means more data support. We want you to connect to as many of your tools as possible.
Throughout 2025, we're creating specialized experiences for every major workflow in your organization. We're moving fast with new features every month, each one transforming Super from a tool you use into a partner that actively helps get work done. From proactive insights based on team patterns to custom workflow templates for common business processes, we're building an assistant that understands what matters in your specific context.
And if you want to get Super for your team - book a demo here.

Written by Christophe Pasquier
Chris founded Slite in 2017 and has spent the decade since thinking about how teams actually keep track of what they know. He writes about where the category is going next — agentic knowledge management, context graphs, and the parts of knowledge work AI is quietly rewriting. He's been wrong about the future before. Mostly he's been early. Find him @Christophepas on Twitter!



