AI search is broken, but we can fix it.

You've just implemented the fanciest Retrieval-Augmented Generation (RAG, or AI search for mortals) system money can buy.
You've fed it every document, Slack message, and coffee-stained napkin scribble from the last decade. You're ready to crush your company's knowledge management. What could possibly go wrong?
Spoiler alert: A lot.
Here's a sneak peek into your “AI-powered” future:
Ask about your CEO, and you might hear, "According to the data, we have three CEOs: Sarah [that was in 2005], Bob [2021], and a potted plant named Fernando [we like to award our office plants titles in our Slack #random channel]."
When you request a summary of the annual report, it could even potentially answer, "Certainly! Our annual report can be summed up in one image: 'This is fine' dog surrounded by flames. This meme was shared 247 times in various Slack channels discussing our financial performance."
Hilarious? Absolutely.
Helpful? Not so much.
Welcome to the fundamental problem of RAG in AI search. But why does this happen?
First off, who cares? We really do, and here’s why.
We are the builders of Slite, the simplest yet most powerful Knowledge Base one can buy. Last year, we went all in on 1 thing: finally delivering the original promise of our category.
Knowledge Bases in my opinion, have always been broken. People pretended they had "single sources of truth", I never witnessed a true one.
The reality is people nest docs in infinite Google Drives with weird names, no structure, and voila - single source of mess. Or they document some stuff in overcomplicated Notion and Confluence. Lot of data, but what's the use of it if nobody can find or trust it?
AI finally unlocks what was impossible before, reading and organising, cleaning and retrieving for you AI is our only hope.
So in November 2022, I said to my team:
“This is it. We can finally answer all our users questions! If we do AI search well enough, it would literally fix the problem once and for all!”
That was the team reaction:

And indeed, Ask first version was massive. We were the first to release a Knowledge Base AI search, in February 2023, and it did solve so many repetitive questions.
But very fast we saw massive limitations, and when months or year later, we saw our competitors starting to catch up and shipping their own AI search, we saw all of them plagued by the same issues.
Let's start by going through all of them, I'll open up on how we address them.
Why RAG/AI search isn’t “perfect”
Quick 101 on RAG
Before we start, the technology to answer questions on your data is very simple in essence:
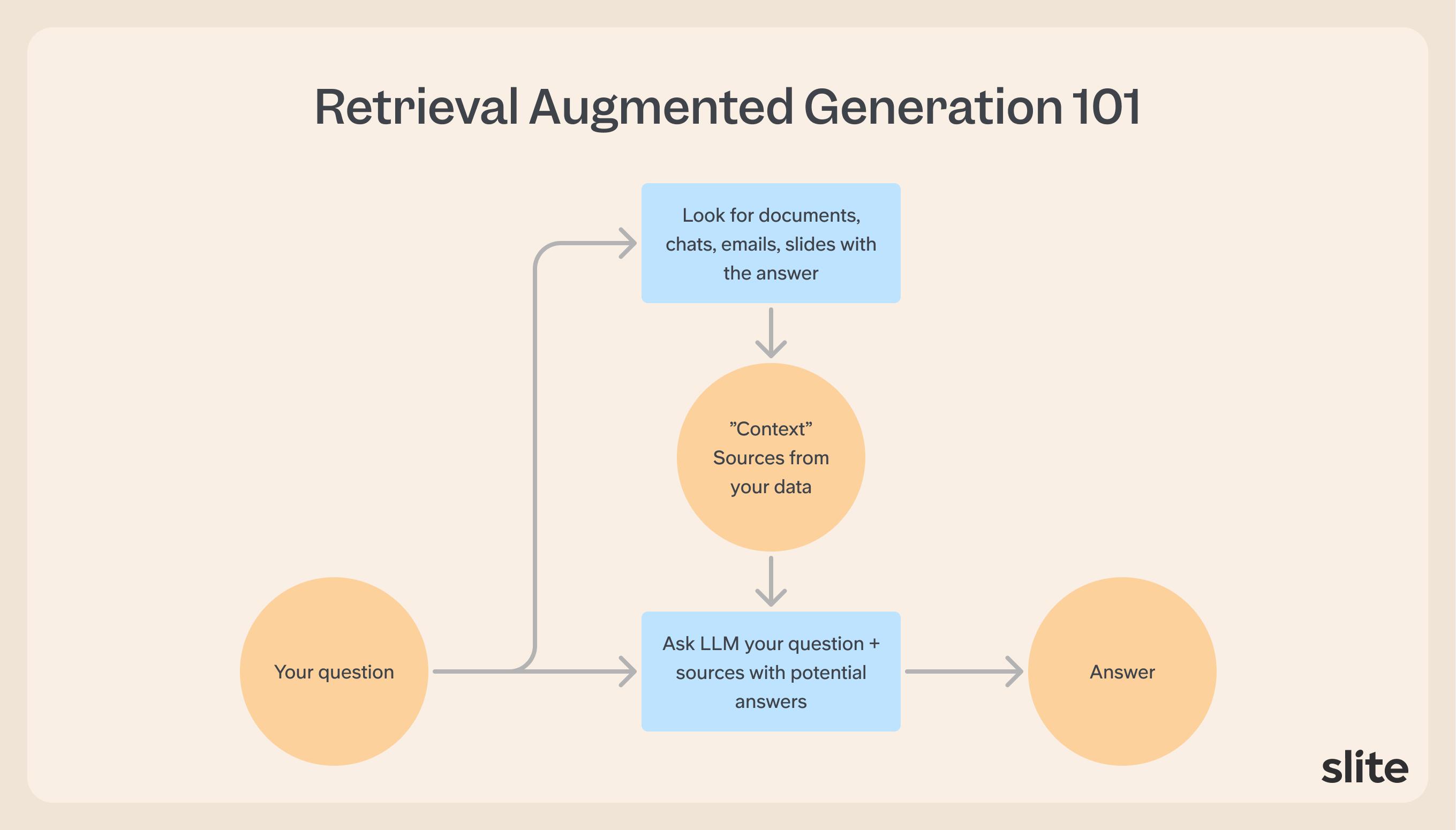
First problem: you don't type the right question
Put too much context and ask a broad question. Let's say, 'How do we onboard new folks?'.
What is obvious in the user mind is very complex for our retrieval engine. Are you referring to new employees? new customers? or maybe how the signup flow to your service works?
All these are valid but the RAG has very limited clue on what to filter out, and what part of the documents found it should answer with.
The obvious: not enough context
Every service in the world will end up offering an AI search. And most of them will have this incredibly short-sighted sentence in the middle of their interface, "Ask anything".
Your data is scattered, there is no way around it. Even GPT 48 and Claude 89 won't be able to answer a question on your private info if it has no access.
NER failing, or when Context Goes MIA
Another thing that can go wrong lies in the keywords extracted to find the documents, transcripts, etc that will hold your answer.
Named Entity Recognition is what allows the AI to extract and weigh important terms and names in a query. In theory, it's supposed to be the superhero that understands "Tumblr" is a product name, not a misspelling, and that "Jack" or "Airbnb" are significant terms, not just random words.
Once NER identifies these crucial words, it applies a boost to them in the search process. This works brilliantly... until it doesn't.
→ Imagine working at Stripe and asking "What is Stripe's security policy?". In your Knowledge Base, it might be the most common word. But NER will logically boost the Stripe keyword, which is not the important word in this context. It will result in a lot of noise.
→ Ask about Python updates , referring to the famous programming language, and get a detailed report on the mating habits of large snakes
Those are examples where NER (Named Entity Recognition) went wrong.
The challenge here lies in the inherent ambiguity of language and the limitations of current NER systems. While they excel at identifying known entities, they struggle with context-dependent meanings and domain-specific jargon.
Recency bias
Another big AI search issue is of time.
When you ask AI, “what are we currently working on?”, it will struggle to understand the meaning of current, does the user mean week, month, or day? None of the keywords needed for search to perform are present ("March" or "2024" etc) in the query. And you probably have only update and creation date to give to the LLM.
But as a user, you’d want it to always refer to latest information. That’s why many search engines put a “content decaying mechanism” in place.
In practice, it's essentially teaching your AI to have some recency bias. The decay mechanism in AI is an attempt to model the relevance of information over time:
- This Slack thread? it will decay in 3 months
- This meeting transcripts? in 6 months
- This handbook? a couple of year
Problem is, this concept varies wildly across different types of data and across contexts. Financial reports may become obsolete quickly, while foundational company policies remain relevant for years. But it's hard to intuit from the documents themselves, especially if they are stored in the same platform.
Balancing recency with relevance is a weirdly complex optimization problem for AI search.
Jugling with multiple formats
Your company's knowledge isn't just trapped in PDFs. That would be too simple.
You've got:
- Word documents with dozens formatting changes
- PDF with the most exotic formatting, or even actually scanned papers.
- Excel sheets with half REF! errors
- PowerPoint presentations with more animations than a Pixar movie
- Slack messages that are 90% emojis and GIFs
- Handwritten notes that look like they were scribbled by a doctor during an earthquake
Each of these document types comes with its own set of challenges. Word docs might have tracked changes that confuse the AI. Excel sheets could have complex formulas that look like gibberish when extracted. PowerPoints might lose all context without the presenter's notes. And Slack? Well, good luck teaching AI to interpret "🚀🌙💎🙌" as "Our Q4 projections are looking great!"
Here's where it gets really fun. Even if your AI manages to decipher all these document types, now it has to figure out how to weigh them against each other. Should a formal report carry more weight than a quick Slack message? What if that Slack message is from the CEO announcing a major strategy shift?
Your AI might end up treating a coffee-stained napkin with a hastily scrawled idea as equally important as a 50-page technical specification. Suddenly, your next product launch is based on a mix of rigorous market research and that "eureka" moment Bob had after his third espresso.
AI hallucinates, by design
You've seen this disclaimer every time you opened an AI tool lately:
Hallucinations are a byproduct of the LLM's training to maintain coherence and provide complete responses. The model doesn't have a clear boundary between its training data and the specific information in your Knowledge Base. When it encounters gaps, it fills them with plausible-sounding information drawn from its general knowledge, leading to a mix of fact and fiction that can be hard to disentangle.
There IS a way to make RAG perfect
At this point, we’ve spent 2 years of constant improvement on our Knowledge Base "Ask" feature.
We came to realise we needed to think outside of the box to properly crack the challenges above, and we built a new product called AskX.
The ultimate company AI search will:
- connect with all your tools
- embrace the fact your data is full of contradiction and outdated info
- act as a pair to the user, mixing search suggestion with great UX to yield the right answers
- improve over time, by flagging knowledge gaps and letting teams add what's missing
- and cover all the questions type you might have at work.
And that's AskX. Check it out, it's the future of Enterprise search.
—
Now, I hope I made this clear: AI is not magic, no solution can give you 100% resolution. While RAG will get tremendously better, it will always have gaps. So, while we're charging towards AI-powered knowledge management, keep your sense of humor handy.

Written by Christophe Pasquier
Chris founded Slite in 2017 and has spent the decade since thinking about how teams actually keep track of what they know. He writes about where the category is going next — agentic knowledge management, context graphs, and the parts of knowledge work AI is quietly rewriting. He's been wrong about the future before. Mostly he's been early. Find him @Christophepas on Twitter!



