Fixing our trust issues with AI

Not everyone was ready but let's face it: 2023 is the new 2030, and we're all using robots.
As the trend continues, whether we love it or hate it, one issue will arise: we are going to have a trust issue with robots. Especially when we trust it with our work.
When your chatbot feeds you bad information, or developers introduce bugs because they coded with Copilot, or your content gets squashed by Google Search detection, you'll think twice before using AI at work.
Let's take a simple example. You're a student trying to cheat on a math exam and ask ChatGPT a mathematical question. It gets the answer wrong.
This could just be a cautionary tale: Don't trust a robot to do your homework for you without a backup source, like a textbook, or your brain.
Lesson learned. However, the math example represents a greater problem: if you don't know any better, the robot sounds authoritative. It sounds smart. It sounds right.
And when the questions leave the territory of yes-or-no, right-or-wrong, black-or-white, the answers become even less trustworthy.
But work applications represent far greater danger. Let's say you are working in HR at a lean software startup, finalizing the contract of a new employee named Joan. Your team has a robot "librarian" that can sort through your documentation quickly and deliver answers. So you ask it, "What should Joan's salary be?"
Before you realize it, Joan is paid a million a year. Joan is very happy, and your company just cut its runway in half.
AI is doomed to fail
The problem is large language models are not intelligent. Or rather we're not sure they are just yet. They are very good at completing our sentences, and while this skill is absolutely astonishing, and could exceed our own capabilities very soon, it makes them doomed to fail.
First, because truth is a variable concept, second because AI will lack context.
But enough with the hypotheticals, let's speak of actual applications. We already created Ask, a "robot librarian" as described above. It's an assistant we've built for our knowledge base service Slite. It lets our users read through all their documents, decisions, and deliver answers to their questions.
When you try it, you will both be amazed (if I do say so myself) and realize its shortcomings:
- Some questions can't be answered, because the answer is not written down
- Some of your documents are wrong or outdated
- And some documents contradict each other
What if our robot librarian was a real person, an actual librarian, going through the massive library of documentation your team had built over the years?
The problems would be the same.
No matter how good you are at comprehending what's written, you can't fix the 3 problems above.
You might bring no answer. Disappointing, but acceptable.
But you also might bring the wrong answer. Misleading, and unacceptable.
That's the biggest challenge we need to fix when bringing AI in business tools. So we're taking a strong stance as we build Ask, one we believe all builders mingling with AI need to adopt.
We need to make AI succeed, even when it fails. By designing around its limitations.
UX to the rescue
We need to make AI succeed, even when it fails.
To do so we considered each failure scenario, and considered dedicated solutions. Here is how it looked liked in the case of Ask, our knowledge base assistant. Keep in mind some of the solutions below were exploration and won't be implemented as such.
1️⃣ Your knowledge is incomplete
Failure example number one: Your team mate comes down with a cold and asks the knowledge base something simple:
How can I report sick days?
Basic, but if not written down, AI can't answer.
At Slite, we've always believed team knowledge should be seen as an organic, living entity. Some of it is already written, some of it is nascent, some of it is actually yet to see the light of day. And for the latter, we built a dedicated form factor, called Discussions.
Discussions works as it sounds: it lets you discuss, decide - and log the decision - on important topics.
The same form factor can let you log answers to unanswered questions. So if you don't have an answer, Ask will prompt you to ask your teammates.
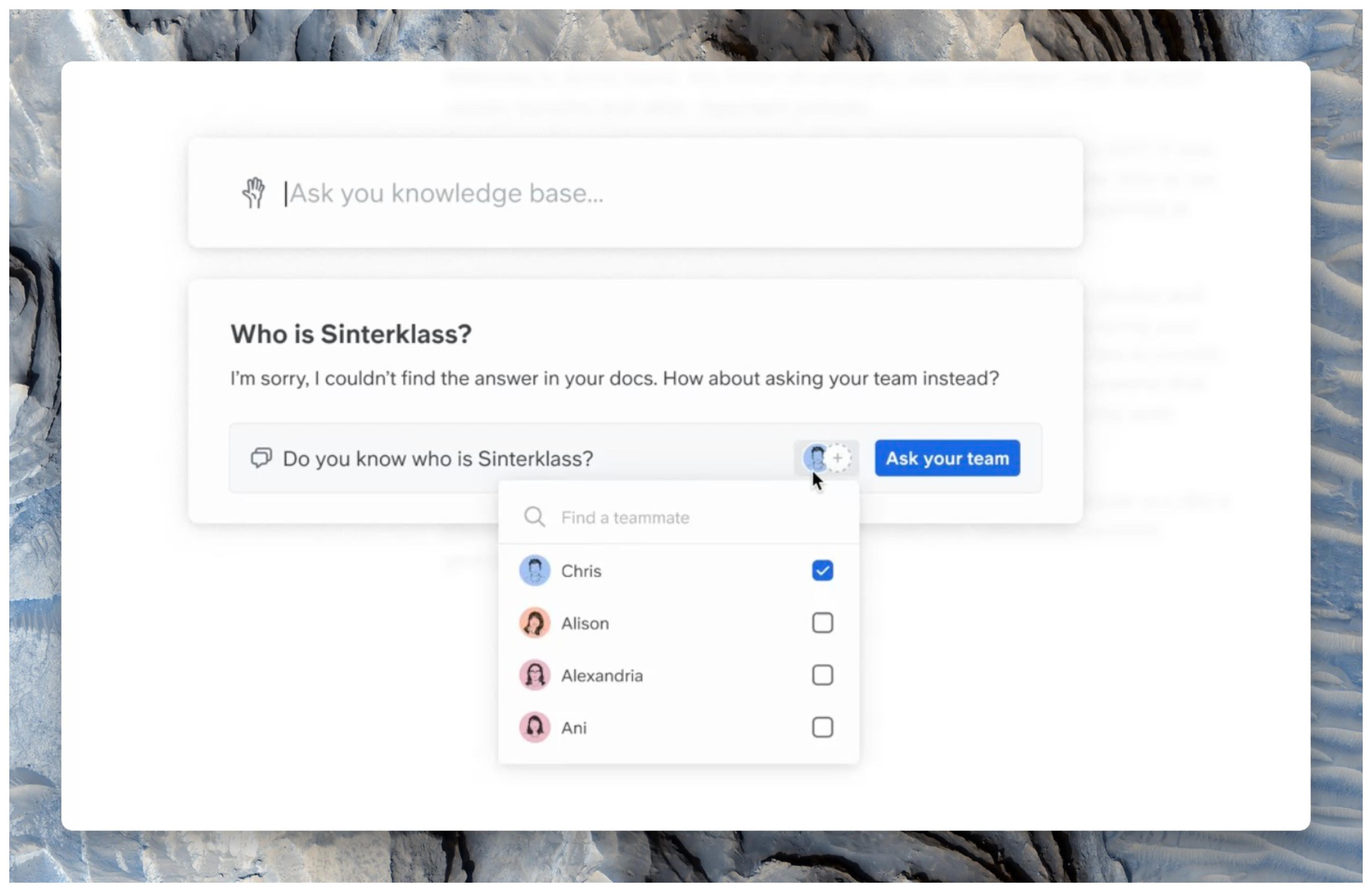
All of a sudden, what was a problematic scenario turns into a chance for your team to strengthen its brain.
2️⃣ Your knowledge is outdated
Failure scenario number two: a new developer joins your team and asks the knowledge base,
"How can I setup and run our codebase locally?"
The answer comes in, and looks sure and accurate. But when the dev runs the commands, it fails. And when looking at the source, realizes the documentation was written in 2019.
That's an issue, but one from the content itself. An issue they would have faced with regular search, minus the pain to sift through all the results.
But of course we still need to make our robot succeed, even when it fails!
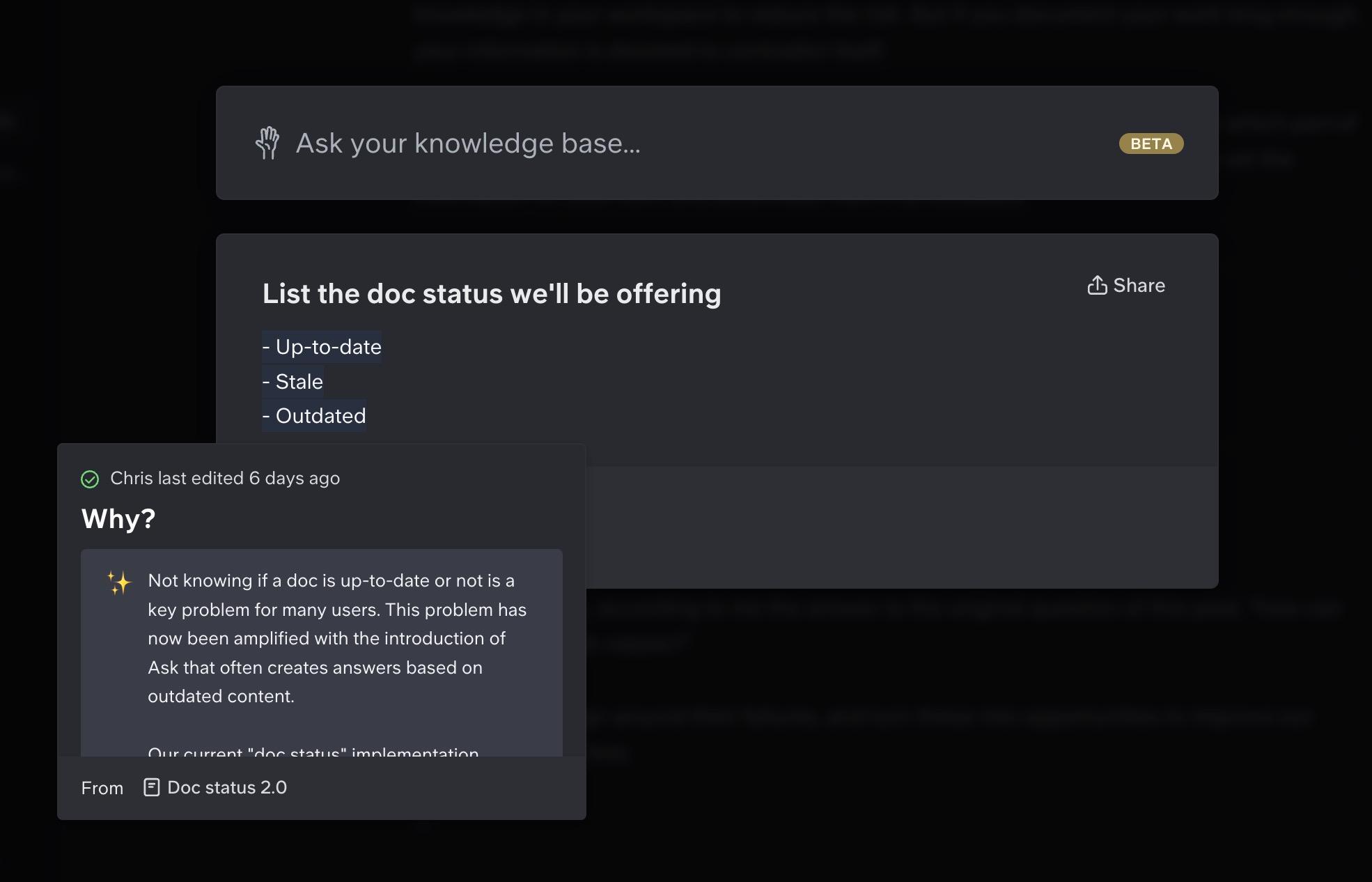
In this case, we introduced document status to solve it. When you visit an outdated doc, you'll have a button to notify the owner this doc is outdated. This will trigger your AI assistant to ignore that particular doc for the time being.
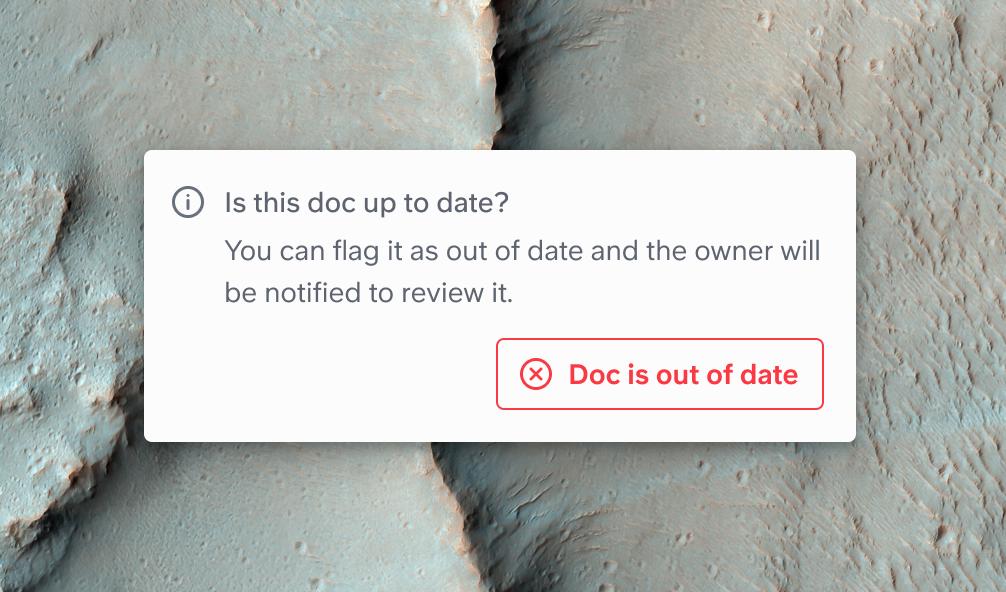
All of a sudden, what was a problematic scenario turns into a chance for your team to curate only the most accurate information, and to refresh its brain.
3️⃣ Your knowledge is in contradiction
The last failure scenario is the most complicated one. In fact, here is a real example from building our own product:
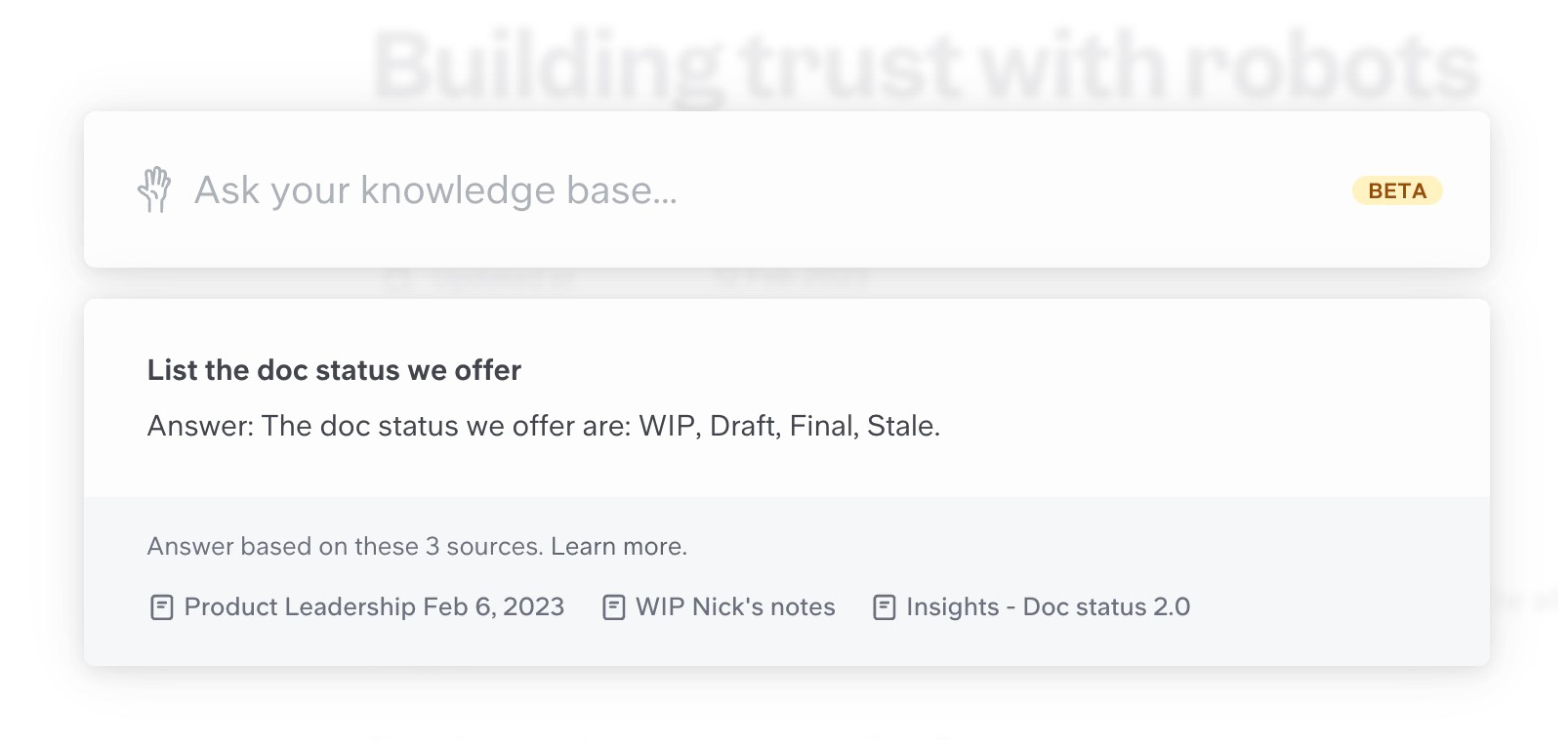
Remember the "status" feature I talked about above? We currently offer three statuses on Slite docs: outdated, up to date and stale .
But we used to offer wip and final ; and we discussed having draft as part of the doc UI as well. However, we never launched those options.
In various docs, all of these are written, which confuses our robot assistant. If one doc says A, the other says B... what should the librarian say?
This is the most complex challenge, not perfectly solved yet, but also the most interesting one.
You can mark docs with wrong answers as outdated of course. You can also keep only static knowledge in your workspace to reduce the risk. But if you document your work long enough, your information is doomed to contradict itself.
To solve that, we detect the sources we used to give your answer, and we show which part of a document was likely used to generate the content. On the fly, you can already vet the information on your own, and potentially mark it as outdated.
Make AI succeed, even when it fails
So that's it, that's our hint of answer to the original question of this post, "how can we build trust with robots?"
We need to design around their failures, and turn these into opportunities to improve our experience over time. AI is just a technology, we need our best craft and creativity to turn it into tools actually usable.
--
Hope this will help other tool builders, and give you a new perspective on what we can expect from AI in our work tools.
If you want to follow more of our journey, follow me on Twitter, share this post, and of course, get access to Slite and to Ask today!
Chris

Written by Christophe Pasquier
Chris founded Slite in 2017 and has spent the decade since thinking about how teams actually keep track of what they know. He writes about where the category is going next — agentic knowledge management, context graphs, and the parts of knowledge work AI is quietly rewriting. He's been wrong about the future before. Mostly he's been early. Find him @Christophepas on Twitter!



